Семантическое ядро — как составить правильно? UNIX-подобная операционная система: пишем ядро на языке C
Когда начинаешь читать пособия по продвижению сайта, всё всегда начинается с создания семантического ядра. Для новичков этот первый шаг – самый трудный. Кроме того, что не сразу становится понятно, что такое это семантическое ядро, ещё и не ясно, какую оно имеет цель и как его правильно создавать.
В этой статье мы расскажем о том, как правильно создавать семантическое ядро сайта. А также вы узнаете о том, что это такое и для чего его делают. На самом деле в понятии семантического ядра нет ничего сложного и трудного. Давайте разбираться.
Никто ещё не отвечал на вопрос о том, что такое семантическое ядро такими простыми словами, как сейчас это сделаем мы. Итак, семантическое ядро сайта - это список ключевых фраз, по которым он будет продвигаться. Всё! Весь смысл понятия в одном коротком ясном предложении. И не надо ничего мутить умными терминами.
Если капнуть в термин глубже, то семантика - это наука, которая занимается смысловым наполнением лексических единиц. Говоря простыми словами, семантика изучает смысл чего-либо. В SEO семантическое ядро даёт понять смысл всего сайта, его какого-либо раздела или отдельной взятой статьи. Это становится понятно поисковику, посетителю, всем разработчикам, которые будут работать с сайтом.
Семантическое ядро без преувеличения - это фундамент всего продвижения.
Как использовать семантическое ядро и для чего оно нужно
Функциями семантического ядра можно назвать следующие аспекты продвижения сайта:
- Самая главная задача семантического ядра - это понимание структуры сайта и его наполненности. Глядя на него, можно представить себе, какие разделы у сайта будут, и какие статьи будут в каждом разделе. И, таким образом, все недостатки и неудобства структуры сразу видны, и их можно устранить ещё на раннем этапе.
- Семантика задаёт вектор контента. Благодаря лучшему понимаю структуры сайта, можно подобрать наиболее релевантные и эффективные ключевые фразы.
- Семантическое ядро - это контент-план сайта на долгие годы вперёд. Каждый раз, когда нужно написать статьи, можно заглянуть туда и увидеть, какой контент планировался и в каком разделе сайта он должен быть.
- Если планируется платное продвижение сайта, например, за счёт контекстной рекламы, то благодаря семантическому ядру можно рассчитать стоимость продвижения.
Как сделать семантическое ядро
Для начала надо определиться, откуда вы будете брать ключевые фразы для ядра. Наиболее лучший для новичков источник - это сервис Яндекс WordPStat, который показывает то, сколько раз в месяц вводился тот или иной запрос в поиск Яндекс. У WordStat есть разнообразные полезные функции, например можно фильтровать запросы по регионам или устройствам, смотреть похожие запросы и многое другое. А самое главное, что он абсолютно бесплатный. Подробнее об этом .
Можно использовать и разнообразные платные программы, но новичкам лучше подойдёт именно WordStat, в виду его простоты. Кроме этого, он подойдёт не только для Рунета, где Яндекс преобладает. Если вы продвигаете сайт в пределах СНГ, то его можно смело использовать, и статистка по Google будет примерно такая же.
Основная суть создания семантического ядра - это сбор ключевых фраз, которые так или иначе подходят под тематику сайта. Их надо их как-то оформить, систематизировать. Для этого лучше всего подходят таблицы, например Excel, таблицы в Google Doc или аналогичные.
И для большей эффективности, в таблице семантического ядра можно добавить дополнительные графы:
- Естественно, должна быть графа с самой ключевой фразой.
- Конечно же, графа с наименование рубрики сайта, где эта фраза будет использоваться.
- Можно добавить графу с мета-тегами titile и description и сразу написать заголовок и описание к статье с использованием заданной ключевой фразы. Во-первых, сразу будет понятно, о чём писать статью, во-вторых, потом не надо будет ломать голову и придумывать это.
- Можно сделать графу для указания количества символов в статье по заданной ключевой фразе, чтобы лучше понимать контент-план.
- Если речь идёт о продвижении контекстной рекламой, нужно добавить и стоимость рекламы для каждого запроса.
- Всё, что должно понадобится можно смело записывать в таблицу сематического ядра. Какого-либо шаблона для этого нет, поэтому делать там можно всё, что угодно и удобно.
Частые ошибки при создании семантического ядра
Теперь вы знаете, как правильно создать семантическое ядро сайта. Давайте рассмотрим напоследок, какие частые ошибки бывают у начинающих оптимизаторов.
- Если ядро предусматривает разделение сайта на рубрики, то частой ошибки является создание глубоких уровней вложенности. Рекомендуется второй уровень и не далее. То есть, можно сделать рубрику, подрубрику и всё, дальше делить на более мелкие рубрики уже нельзя.
- Новички могут игнорировать низкочастотные запросы, так как считают, что использовать их нецелесообразно, всё равно они не принесут много трафика. Но на самом деле всё наоборот. Для нового сайта нужны именно низкочастотные, никзоконкурентные запросы.
- Нельзя полностью доверять сервису, с помощью которого будут добываться ключевые фразы. А новички поступают именно так. Машины могут ошибаться и выбрать вам не то, что нужно.
- Не нужно создавать статью ради ключевой фразы. Если вы нашли фразы “срочно продать дом” и “продать дом быстро”, то нет смысла делать для них две разные статьи.
В прошлой статье я вам рассказал, но, а сегодня пришло время рассказать о том, как составить семантическое ядро сайта при помощи специальных программ и серверов.
Наступает лето и как-то все труднее и тяжелее становиться вести блог, вот и результат статьи выходят редко что вас наверняка не радует. Не правда ли?
Честно сказать дело вовсе не в летней поре, а в моей «глупости» создания блога на начальном этапе. В общем, я при создании блога отталкивался от своих мыслей, а не от запросов пользователей. В общем, получилось так, что я сам себе отвечал на вопросы, смешно.
В одном из прошлых своих постов, я уже, как то писал для чего нужно СЯ сайту и что это такое, где раскрыл основу основ его создания, пора бы, наверное, и к практике создания семантического ядра перейти.
как создать семантическое ядро для сайта
В прошлой статье я в основном рассказывал теорию, но как показывает практика не всегда все пользователи понимают такой материал, так что представляю пошаговую инструкцию, которую можно взять за основу и сделать своё семантическое ядро без особых усилий. Да именно за основу, так как прогресс не стоит на месте и, возможно, уже есть более продвинутые способы создания ядра для сайта.
Ищем конкурентов для составления семантического ядра сайта
Итак, первым делом мы должны определиться, про что и о чём будет наш будущий сайт. Я возьму за основу тему «экология окружающей природы» и подберу к ней ключевые слова. Для определения основных ключей я возьму сайт конкурента находящейся на первых местах и Google.
Как вы понимаете я возьму за основу первые три сайта в выдаче Яндекс.
сезоны-года.рф
zeleneet.com
biofile.ru
Отбираем запросы конкурентов - автоматически
На этом шаге нам хорошо подойдёт любой сайт, который может автоматически определить запросы сайта, подходящие для его продвижения в топ. Я предпочитаю использовать , какой вы предпочтёте сервер - это сугубо ваше мнение, о котором вы можете написать мне в комментариях и обсудить.
Добавляем нашего донора, а не наш сайт!
Как вы уже догадались я взял один из трёх сайтов, - вы же должны взять несколько. Жмём далее…
Как видите, я отобрал только первые 10 запросов для наглядного примера. Вы должны собрать как можно больше ключевых слов также не поленитесь подумать, как вы спросили у гугла, чтоб найти ответ на ваш вопрос, которые собираетесь размещать в интернете на своём блоге или сайте. Переходим к следующему этапу формирования семантического ядра своими руками.
Как вы уже поняли вам осталось только экспортировать базу ключевых слов и перейти к следующему шагу на пути создания семантического ядра сайта, который вы сделаете самостоятельно. Не забываете проставить галочки на ключевых словах, которые пытаетесь сохранить в файле exel.
Отбираем НЧ СЧ и ВЧ запросы
На этом этапе нам поможет сервер, осторожно партнерская ссылка, зарегистрироваться в rookee.ru. Переходим на него и создаём новую рекламную кампанию используя сайт нашего конкурента.
Добавляем сайт и следуем пошаговой инструкции интернет ресурса.
Теперь нужно немного подождать, чтоб робот отсканировал сайт и дал вам наиболее интересные запросы, которые вы также можете применить впоследствии. Вот мой результат.
Как видите, система нашла 299 запроса, но они меня не интересуют и я просто возьму их удалю и добавлю те 10, которые мне дал seopult на первом этапе. Кстати, один запрос должен оставаться, иначе не сможете все удалить. У меня после удаления получилось так. Когда я добавлю основную базу запросов, я этот ключ удалю, чтоб он мне не мешал, так как он для меня не актуален. Теперь добавляем запросы, которые получили ранее.
У меня после удаления получилось так. Когда я добавлю основную базу запросов, я этот ключ удалю, чтоб он мне не мешал, так как он для меня не актуален. Теперь добавляем запросы, которые получили ранее.
Теперь нам нужно перейти в папку «запросы» и немного подождать, когда запросы просканирует поисковый робот. У меня в итоге вышло так, что все слова оказались НК (низкоконкурентными), которые мне вполне подходят для создания сайта и привлечения первых читателей на блог.
Если у вас есть слова со значением ВК (высокая конкуренция) или СК (средняя конкуренция), то на первом этапе формирования ядра вам следует от них отказаться и выбрать только низкую конкуренцию.
Экспортируем слова и переходим к следующему завершающему шагу. Так как у меня все слова по низкой конкуренции я ничего не удалял, у вас, возможно, другая ситуация. Но я вас убедительно прошу удалить средне и высоко конкурентные запросы, так как это лишние ваши затраты.
Составляем семантическое ядро для сайта
Для завершающего этапа нам понадобится программа Key Collector,я буду использовать её бесплатный прототип, который вы легко можете найти в интернете. Название этой программы я, пожалуй, оставлю вам в виде домашнего задания. Итак, открываем программу и вписываем свой найденные ключи, у меня их пока 9 штук.
Как мы видим, что из 9 запросов нам лучше писать про прибор для измерения влажности воздуха. Это пример с одним ключевым словом, которое актуально под НЧ запрос на указанную тематику.
Не забываете, что программа способна также подобрать 1 тыс. слов по основному запросу с его словоформами, для этого просто впишите слова в красную вкладку «пакетный сбор слов из Яндекс worstat».
После того как вы отберёте максимальное количество релевантных слов не забудьте их отсортировать по значимости начиная с меньшего. Старайтесь также делать хорошую перелинковку вашей статье, - это вызовет улучшение поведенческих фактов на вашем ресурсе.
Ну вот и все, что-то я затянул с работой. А вы как делаете СЯ для своего интернет-магазина? напишите мне об этом в комментариях.
P.S. Вы также можете получать мои новые статьи на почту просто подписавшись на rss рассылку и узнавать о моих секретах и методах первыми. А вы, как составляете семантическое ядро сайта? Напишите, мне о своем способе в комментариях, подискутируем.
Данный цикл статей посвящён низкоуровневому программированию, то есть архитектуре компьютера, устройству операционных систем, программированию на языке ассемблера и смежным областям. Пока что написанием занимаются два хабраюзера - и . Для многих старшеклассников, студентов, да и профессиональных программистов эти темы оказываются весьма сложными при обучении. Существует много литературы и курсов, посвящённых низкоуровневому программированию, но по ним сложно составить полную и всеохватывающую картину. Сложно, прочитав одну-две книги по ассемблеру и операционным системам, хотя бы в общих чертах представить, как же на самом деле работает эта сложная система из железа, кремния и множества программ - компьютер.
Каждый решает проблему обучения по-своему. Кто-то читает много литературы, кто-то старается поскорее перейти к практике и разбираться по ходу дела, кто-то пытается объяснять друзьям всё, что сам изучает. А мы решили совместить эти подходы. Итак, в этом курсе статей мы будем шаг за шагом демонстрировать, как пишется простая операционная система. Статьи будут носить обзорный характер, то есть в них не будет исчерпывающих теоретических сведений, однако мы будем всегда стараться предоставить ссылки на хорошие теоретические материалы и ответить на все возникающие вопросы. Чёткого плана у нас нет, так что многие важные решения будут приниматься по ходу дела, с учётом ваших отзывов.
Возможно, мы умышленно будем заводить процесс разработки в тупик, чтобы позволить вам и себе полностью осознать все последствия неверно принятого решения, а также отточить на нем некоторые технические навыки. Так что не стоит воспринимать наши решения как единственно верные и слепо нам верить. Еще раз подчеркнём, что мы ожидаем от читателей активности в обсуждении статей, которая должна сильно влиять на общий процесс разработки и написания последующих статей. В идеале хотелось бы, чтобы со временем некоторые из читателей присоединились к разработке системы.
Мы будем предполагать, что читатель уже знаком с основами языков ассемблер и Си, а также элементарными понятиями архитектуры ЭВМ. То есть, мы не будем объяснять, что такое регистр или, скажем, оперативная память. Если вам не будет хватать знаний, вы всегда можете обратиться к дополнительной литературе. Краткий список литературы и ссылки на сайты с хорошими статьями есть в конце статьи. Также желательно уметь пользоваться Linux, так как все инструкции по компиляции будут приводиться именно для этой системы.
А теперь - ближе к делу. В оставшейся части статьи мы с вами напишем классическую программу «Hello World». Наш хеллоуворлд получится немного специфическим. Он будет запускаться не из какой-либо операционной системы, а напрямую, так сказать «на голом железе». Перед тем, как приступить непосредственно к написанию кода, давайте разберёмся, как же конкретно мы пытаемся это сделать. А для этого надо рассмотреть процесс загрузки компьютера.
Итак, берем свой любимый компьютер и нажимаем самую большую кнопочку на системном блоке. Видим веселую заставку, системный блок радостно пищит спикером и через какое-то время загружается операционная система. Как вы понимаете, операционная система хранится на жёстком диске, и вот тут возникает вопрос: а каким же волшебным образом операционная система загрузилась в ОЗУ и начала выполняться?
Знайте же: за это отвечает система, которая есть на любом компьютере, и имя ей - нет, не Windows, типун вам на язык - называется она BIOS. Расшифровывается ее название как Basic Input-Output System, то есть базовая система ввода-вывода. Находится BIOS на маленькой микросхемке на материнской плате и запускается сразу после нажатия большой кнопки ВКЛ. У BIOS три главных задачи:
- Обнаружить все подключенные устройства (процессор, клавиатуру, монитор, оперативную память, видеокарту, голову, руки, крылья, ноги и хвосты…) и проверить их на работоспособность. Отвечает за это программа POST (Power On Self Test – самотестирование при нажатии ВКЛ). Если жизненно важное железо не обнаружено, то никакой софт помочь не сможет, и на этом месте системный динамик пропищит что-нибудь зловещее и до ОС дело вообще не дойдет. Не будем о печальном, предположим, что у нас есть полностью рабочий компьютер, возрадуемся и перейдем к рассмотрению второй функции BIOS:
- Предоставление операционной системе базового набора функций для работы с железом. Например, через функции BIOS можно вывести текст на экране или считать данные с клавиатуры. Потому она и называется базовой системой ввода-вывода. Обычно операционная система получает доступ к этим функциям посредством прерываний.
- Запуск загрузчика операционной системы. При этом, как правило, считывается загрузочный сектор - первый сектор носителя информации (дискета, жесткий диск, компакт-диск, флэшка). Порядок опроса носителей можно задать в BIOS SETUP. В загрузочном секторе содержится программа, иногда называемая первичным загрузчиком. Грубо говоря, задача загрузчика - начать запуск операционной системы. Процесс загрузки операционной системы может быть весьма специфичен и сильно зависит от её особенностей. Поэтому первичный загрузчик пишется непосредственно разработчиками ОС и при установке записывается в загрузочный сектор. В момент запуска загрузчика процессор находится в реальном режиме.
На картинке изображена поверхность дискового накопителя. У дискеты 2 поверхности. На каждой поверхности есть кольцеобразные дорожки (треки). Каждый трек делится на маленькие дугообразные кусочки, называемые секторами. Так вот, исторически сложилось, что сектор дискеты имеет размер 512 байт. Самый первый сектор на диске, загрузочный сектор, читается BIOS"ом в нулевой сегмент памяти по смещению 0x7С00, и дальше по этому адресу передается управление. Начальный загрузчик обычно загружает в память не саму ОС, а другую программу-загрузчик, хранящуюся на диске, но по каким-то причинам (скорее всего, эта причина - размер) не влезающую в один сектор. А поскольку пока что роль нашей ОС выполняет банальный хеллоуворлд, наша главная цель - заставить компьютер поверить в существование нашей ОС, пусть даже и на одном секторе, и запустить её.
Как устроен загрузочный сектор? На PC единственное требование к загрузочному сектору - это содержание в двух его последних байтах значений 0x55 и 0xAA - сигнатуры загрузочного сектора. Итак, уже более-менее понятно, что нам нужно делать. Давайте же писать код! Приведённый код написан для ассемблера yasm .
section . text
use16
org 0x7C00 ; наша программа загружается по адресу 0x7C00
start:
mov ax , cs
mov ds , ax ; выбираем сегмент данных
mov si , message
cld ; направление для строковых команд
mov ah , 0x0E ; номер функции BIOS
mov bh , 0x00 ; страница видеопамяти
puts_loop:
lodsb ; загружаем очередной символ в al
test al , al ; нулевой символ означает конец строки
jz puts_loop_exit
int 0x10 ; вызываем функцию BIOS
jmp puts_loop
puts_loop_exit:
jmp $ ; вечный цикл
message:
db "Hello World!" , 0
finish:
times 0x1FE - finish+ start db 0
db 0x55 , 0xAA ; сигнатура загрузочного сектора
Эта короткая программа требует ряда важных пояснений. Строка org 0x7C00 нужна для того, чтобы ассемблер (имеется в виду программа, а не язык) правильно рассчитал адреса для меток и переменных (puts_loop, puts_loop_exit, message). Вот мы ему и сообщаем, что программа будет загружена в память по адресу 0x7C00.
В строках
mov ax , csпроисходит установка сегмента данных (ds) равным сегменту кода (cs), поскольку в нашей программе и данные, и код хранятся в одном сегменте.
mov ds , ax
Далее в цикле посимвольно выводится сообщение «Hello World!». Для этого используется функция 0x0E прерывания 0x10 . Она имеет следующие параметры:
AH = 0x0E (номер функции)
BH = номер видеостраницы (пока не заморачиваемся, указываем 0)
AL = ASCII-код символа
В строке « jmp $ » программа зависает. И правильно, незачем ей выполнять лишний код. Однако чтобы компьютер опять заработал, придется перезагрузиться.
В строке « times 0x1FE-finish+start db 0 » производится заполнение остатка кода программы (за исключением последних двух байт) нулями. Делается это для того, чтобы после компиляции в последних двух байтах программы оказалась сигнатура загрузочного сектора.
С кодом программы вроде разобрались, давайте теперь попробуем скомпилировать это счастье. Для компиляции нам понадобится, собственно говоря, ассемблер - выше упомянутый
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его
вместе!
Небольшое предисловие
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
- мозговой штурм - анализ базовых фраз и подготовка парсинга
- парсинг - расширение базовой семантики на основе Вордстат и других источников
- отсев - отсев после парсинга
- анализ - анализ частотности, сезонности, конкуренции и других важных показателей
- доработка - групировка, разделение коммерческих и информационных фраз ядра
О наиболее важных этапах сбора и пойдет речь ниже!
ВИДЕО - составление семантического ядра по конкурентам
Мозговой штурм при создании семантического ядра — напрягаем мозги
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
- seo блог
- сео блог
- блог про сео
- блог про seo
- продвижение
- продвижение проекта
- раскрутка
- раскрутка
- продвижение блогов
- продвижение блога
- раскрутка блогов
- раскрутка блога
- продвижение статьями
- статейное продвижение
- miralinks
- работа в sape
- покупка ссылок
- закупка ссылок
- оптимизация
- оптимизация страницы
- внутренняя оптимизация
- самостоятельная раскрутка
- как раскрутить ресурс
- как раскрутить свой сайт
- как раскрутить сайт самому
- как раскрутить сайт самостоятельно
- самостоятельная раскрутка
- бесплатная раскрутка
- бесплатное продвижение
- поисковая оптимизация
- как продвинуть сайт в яндексе
- как раскрутить сайт в яндексе
- продвижение под яндекс
- продвижение под гугл
- раскрутка в гугл
- индексация
- ускорение индексации
- выбор донора сайту
- отсев доноров
- раскрутка постовыми
- использование постовых
- раскрутка блогами
- алгоритм яндекса
- апдейт тиц
- апдейт поисковой базы
- апдейт яндекса
- ссылки навсегда
- вечные ссылки
- аренда ссылок
- арендованные ссылке
- ссылки с помесячной оплатой
- составление семантического ядра
- секреты раскрутки
- секреты раскрутки
- тайны seo
- тайны оптимизации
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :

Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Чистка семантики
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:

Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
курсы поисковой оптимизации продам раскрученный сайт
Анализ семантического ядра
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Экспорт и группировка семантического ядра
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:

Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
- такие частотные запросы, как должны иметь намного больший хвост из менее частотных фраз, чем мы видим
- сео новости
- всплыл новый ключ, который мы не учли ранее — статьи сео . Необходимо проанализировать этот ключ
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
- лучший seo блог
- seo новости
- статьи seo
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
Финальный отсев
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:


Затем проверяем стоимость получения одного перехода по нашим ключевым словам:

Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.
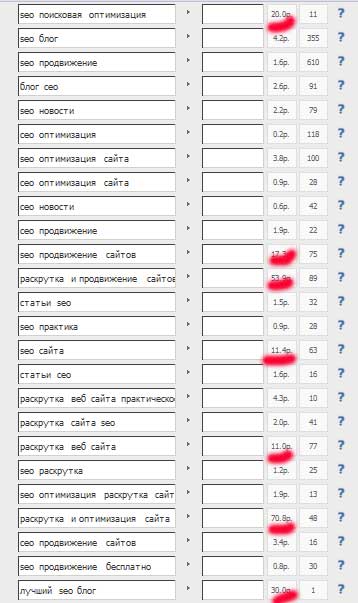
Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
Полезная информация!
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Кластеризация семантического ядра
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
- Подбор и анализ поисковых запросов
- Группировка запросов по страницам сайта (создание посадочных страниц)
- Подготовка seo текстов для посадочных страниц на основе группы запросов для этих страниц
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
- Один и тот же интент могут иметь несколько запросов не имеющих какой-либо семантической близости, например – “обслуживание автомобиля” и “записаться на ТО”
- Запросы, имеющие абсолютную семантическую близость могут содержать в себе кардинально разные интенты, например, хрестоматийная ситуация – “мобильник” и “мобильники”. В одном случае пользователь хочет купить телефон, а в другом посмотреть фильм
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
- Система поочередно вводит все поданные ей запросы в поисковую выдачу и запоминает результаты из ТОП
- После поочередного ввода запросов и сохранения результатов, система ищет пересечения в выдаче. Если один и тот же сайт одним и тем же документом (страница сайта) находится в ТОП сразу по нескольким запросам, то эти запросы теоретически можно объединить в одну группу
- Становится актуальным такой параметр, как сила группировки, который говорит системе, сколько именно должно быть пересечений, чтобы запросы можно было добавить в одну группу. К примеру, сила группировки 2 означает, что в выдаче по 2-м разным запросам должно присутствовать не менее двух пересечений. Говоря еще проще – минимум две страницы двух разных сайтов должны присутствовать одновременно в ТОП по одному и другому запросу. Пример ниже.
- При группировках больших семантики становится актуальна логика связей между запросами, на основе которой выделяют 3 базовых вида кластеризации: soft, middle и hard. О видах кластеризации мы еще поговорим в следующих записях этого дневника
UNIX-подобная операционная система интересна для разбора, а также для написания собственного ядра, которое выведет сообщение. Ну что, напишем?
UNIX-подобная операционная система и загрузка x86 машины
Что такое UNIX-подобная операционка? Это ОС, созданная под влиянием UNIX. Но прежде чем заняться написанием ядра для нее, давайте посмотрим, как машина загружается и передает управление ядру.
Большинство регистров x86 процессора имеют четко определенные значения после включения питания. Регистр указателя инструкций (EIP) содержит адрес памяти для команды, выполняемой процессором. EIP жестко закодирован на значение 0xFFFFFFF0. Таким образом, у процессора есть четкие инструкции по физическому адресу 0xFFFFFFF0, что, по сути, – последние 16 байт 32-разрядного адресного пространства. Этот адрес называется вектором сброса.
Теперь карта памяти чипсета гарантирует, что 0xFFFFFFF0 сопоставляется с определенной частью BIOS, а не с ОЗУ. Между тем, BIOS копирует себя в ОЗУ для более быстрого доступа. Это называется затенением (shadowing). Адрес 0xFFFFFFF0 будет содержать только инструкцию перехода к адресу в памяти, где BIOS скопировал себя.
Таким образом, код BIOS начинает свое выполнение. Сначала BIOS ищет загрузочное устройство в соответствии с настроенным порядком загрузочных устройств. Он ищет определенное магическое число, чтобы определить, является устройство загрузочным или нет (байты 511 и 512 первого сектора равны 0xAA55).
После того, как BIOS обнаружил загрузочное устройство, он копирует содержимое первого сектора устройства в оперативную память, начиная с физического адреса 0x7c00; затем переходит по адресу и выполняет только что загруженный код. Этот код называется системным загрузчиком (bootloader).
Затем bootloader загружает ядро по физическому адресу 0x100000. Адрес 0x100000 используется как стартовый адрес для всех больших ядер на x86 машинах.
Все x86 процессоры стартуют в упрощенном 16-битном режиме, называемом режимом реальных адресов. Загрузчик GRUB переключается в 32-битный защищенный режим, устанавливая младший бит регистра CR0 равным 1. Таким образом, ядро загружается в 32-разрядный защищенный режим.
Обратите внимание, что в случае обнаружения ядра Linux, GRUB получит протокол загрузки и загрузит Linux-ядро в реальном режиме. А ядро Linux сделает переключение в защищенный режим.
Что нам понадобится?
- x86 компьютер (разумеется)
- Ассемблер NASM
- ld (GNU Linker)
- Исходный код
Ну и неплохо было бы иметь представление о том, как работает UNIX-подобная ОС. Исходный код можно найти в репозитории на Github.
Точка входа и запуск ядра
Для начала напишем небольшой файл в x86 ассемблере, который будет отправной точкой для запуска ядра. Этот файл будет вызывать внешнюю функцию на C, а затем остановит поток программы.
Как убедиться, что этот код послужит отправной точкой для ядра?
Мы будем использовать скрипт компоновщика, который связывает объектные файлы с целью создания окончательного исполняемого файла ядра. В этом скрипте явно укажем, что бинарный файл должен быть загружен по адресу 0x100000. Этот адрес, является тем местом, где должно быть ядро.
Вот код сборки:
;;kernel.asm bits 32 ;директива nasm - 32 bit section .text global start extern kmain ;kmain определена в C-файле start: cli ;блокировка прерываний mov esp, stack_space ;установка указателя стека call kmain hlt ;остановка процессора section .bss resb 8192 ;8KB на стек stack_space:
Первая инструкция bits 32 не является инструкцией сборки x86. Это директива для ассемблера NASM, которая указывает, что он должен генерировать код для работы на процессоре, работающем в 32-битном режиме. Это не обязательно требуется в нашем примере, однако это хорошая практика – указывать такие вещи явно.
Вторая строка начинается с текстового раздела. Здесь мы разместим весь наш код.
global — еще одна директива NASM, служит для установки символов исходного кода как глобальных.
kmain — это собственная функция, которая будет определена в нашем файле kernel.c. extern объявляет, что функция определена в другом месте.
Функция start вызывает функцию kmain и останавливает CPU с помощью команды hlt. Прерывания могут пробудить CPU из выполнения инструкции hlt. Поэтому мы предварительно отключаем прерывания, используя инструкцию cli.
В идеале необходимо выделить некоторый объем памяти для стека и указать на нее с помощью указателя стека (esp). Однако, GRUB делает это за нас, и указатель стека уже установлен. Тем не менее, для верности, мы выделим некоторое пространство в разделе BSS и поместим указатель стека в начало выделенной памяти. Для этого используем команду resb, которая резервирует память в байтах. После этого остается метка, которая указывает на край зарезервированного фрагмента памяти. Перед вызовом kmain указатель стека (esp) используется для указания этого пространства с помощью команды mov.
Ядро на C
В kernel.asm мы сделали вызов функции kmain(). Таким образом, код на C начнет выполнятся в kmain():
/* * kernel.c */ void kmain(void) { const char *str = "my first kernel"; char *vidptr = (char*)0xb8000; //видео пямять начинается здесь unsigned int i = 0; unsigned int j = 0; /* этот цикл очищает экран*/ while(j < 80 * 25 * 2) { /* пустой символ */ vidptr[j] = " "; /* байт атрибутов */ vidptr = 0x07; j = j + 2; } j = 0; /* в этом цикле строка записывается в видео память */ while(str[j] != "\0") { /* ascii отображение */ vidptr[i] = str[j]; vidptr = 0x07; ++j; i = i + 2; } return; }
* kernel.c void kmain (void ) const char * str = "my first kernel" ; unsigned int i = 0 ; unsigned int j = 0 ; /* этот цикл очищает экран*/ while (j < 80 * 25 * 2 ) { /* пустой символ */ vidptr [ j ] = " " ; /* байт атрибутов */ vidptr [ j + 1 ] = 0x07 ; j = j + 2 ; j = 0 ; /* в этом цикле строка записывается в видео память */ while (str [ j ] != "\0" ) { /* ascii отображение */ vidptr [ i ] = str [ j ] ; vidptr [ i + 1 ] = 0x07 ; i = i + 2 ; return ; |
Наше ядро будет очищать экран и выводить на него строку «my first kernel».
Для начала мы создаем указатель vidptr, который указывает на адрес 0xb8000. Этот адрес является началом видеопамяти в защищенном режиме. Текстовая память экрана – это просто кусок памяти в нашем адресном пространстве. Ввод/вывод для экрана на карте памяти начинается с 0xb8000 и поддерживает 25 строк по 80 ascii символов каждая.
Каждый элемент символа в этой текстовой памяти представлен 16 битами (2 байта), а не 8 битами (1 байт), к которым мы привыкли. Первый байт должен иметь представление символа, как в ASCII. Второй байт является атрибутным байтом. Он описывает форматирование символа, включая разные атрибуты, например цвет.
Чтобы напечатать символ с зеленым цветом на черном фоне, мы сохраним символ s в первом байте адреса видеопамяти и значение 0x02 во втором байте.
0 — черный фон, а 2 — зеленый.
Ниже приведена таблица кодов для разных цветов:
0 - Black, 1 - Blue, 2 - Green, 3 - Cyan, 4 - Red, 5 - Magenta, 6 - Brown, 7 - Light Grey, 8 - Dark Grey, 9 - Light Blue, 10/a - Light Green, 11/b - Light Cyan, 12/c - Light Red, 13/d - Light Magenta, 14/e - Light Brown, 15/f – White.
0 - Black , 1 - Blue , 2 - Green , 3 - Cyan , 4 - Red , 5 - Magenta , 6 - Brown , 7 - Light Grey , 8 - Dark Grey , 9 - Light Blue , 10 / a - Light Green , 11 / b - Light Cyan , 12 / c - Light Red , 13 / d - Light Magenta , 14 / e - Light Brown , 15 / f –White . |
В нашем ядре мы будем использовать светло-серые символы на черном фоне. Поэтому наш байт атрибутов должен иметь значение 0x07.
В первом цикле while программа записывает пустой символ с атрибутом 0x07 по всем 80 столбцам из 25 строк. Таким образом, экран очищается.
Во втором цикле while символы строки «my first kernel» записываются в кусок видеопамяти. Для каждого символа атрибутный байт содержит значение 0x07.
Таким образом, строка отобразится на экране.
Связующая часть
Мы собираем kernel.asm и NASM в объектный файл, а затем с помощью GCC компилируем kernel.c в другой объектный файл. Теперь наша задача – связать эти объекты с исполняемым загрузочным ядром.
Для этого мы используем явный скрипт компоновщика, который можно передать как аргумент ld (наш компоновщик).
/* * link.ld */ OUTPUT_FORMAT(elf32-i386) ENTRY(start) SECTIONS { . = 0x100000; .text: { *(.text) } .data: { *(.data) } .bss: { *(.bss) } }
* link.ld OUTPUT_FORMAT (elf32 - i386 ) ENTRY (start ) SECTIONS 0x100000 ; Text : { * (. text ) } Data : { * (. data ) } Bss : { * (. bss ) } |
Во-первых, мы устанавливаем выходной формат исполняемого файла как 32-битный исполняемый (ELF). ELF – стандартный формат двоичного файла для Unix-подобных систем на архитектуре x86.
ENTRY принимает один аргумент. Он указывает имя символа, которое должно быть точкой входа нашего исполняемого файла.
SECTIONS – самая важная часть, где мы определяем разметку исполняемого файла. Здесь указывается, как должны быть объединены различные разделы и в каком месте они будут размещаться.
В фигурных скобках, следующих за инструкцией SECTIONS, символ периода (.) – представляет собой счетчик местоположения.
Счетчик местоположения всегда инициализируется до 0x0 в начале блока SECTIONS. Его можно изменить, присвоив ему новое значение.
Как уже говорилось, код ядра должен начинаться с адреса 0x100000. Таким образом, мы установили счетчик местоположения в 0x100000.
Посмотрите на следующую строку .text: {*(.text)}
Звездочка (*) является спецсимволом, который будет соответствовать любому имени файла. То есть, выражение *(.text) означает все секции ввода.text из всех входных файлов.
Таким образом, компоновщик объединяет все текстовые разделы объектных файлов в текстовый раздел исполняемого файла по адресу, хранящемуся в счетчике местоположения. Раздел кода исполняемого файла начинается с 0x100000.
После того, как компоновщик разместит секцию вывода текста, значение счетчика местоположения установится в 0x1000000 + размер раздела вывода текста.
Аналогично, разделы данных и bss объединяются и помещаются на значения счетчика местоположения.
Grub и Multiboot
Теперь все файлы, необходимые для сборки ядра, готовы. Но, поскольку мы намеренны загружать ядро с помощью GRUB, нужно еще кое-что.
Существует стандарт для загрузки различных x86 ядер с использованием загрузчика, называемый спецификацией Multiboot.
GRUB загрузит ядро только в том случае, если оно соответствует Multiboot-спецификации.
Согласно ей, ядро должно содержать заголовок в пределах его первых 8 килобайт.
Кроме того, этот заголовок должен содержать дополнительно 3 поля:
- поле магического числа: содержит магическое число 0x1BADB002, для идентификации заголовка.
- поле флагов: сейчас оно не нужно, просто установим его значение в ноль.
- поле контрольной суммы: когда задано, должно возвращать ноль для суммы с первыми двумя полями.
Итак, kernel.asm будет выглядеть таким образом:
;;kernel.asm ;nasm directive - 32 bit bits 32 section .text ;multiboot spec align 4 dd 0x1BADB002 ;магические числа dd 0x00 ;флаги dd - (0x1BADB002 + 0x00) ;контрольная сумма. мч+ф+кс должно равняться нулю global start extern kmain ;kmain определена во внешнем файле start: cli ;блокировка прерываний mov esp, stack_space ;указатель стека call kmain hlt ;остановка процессора section .bss resb 8192 ;8KB на стек stack_space:
; ; kernel . asm ; nasm directive - 32 bit bits 32 section . text ; multiboot spec align 4 dd 0x1BADB002 ; магическиечисла dd 0x00 ; флаги dd - (0x1BADB002 + 0x00 ) ; контрольнаясумма. мч+ ф+ ксдолжноравнятьсянулю global start extern kmain ; kmain определенавовнешнемфайле start : cli ; блокировкапрерываний mov esp , stack _ space; указательстека call kmain hlt ; остановкапроцессора |
 Чёрный майнинг: как зарабатывают деньги через чужие компьютеры Скрипт майнинга криптовалюты как его удалить
Чёрный майнинг: как зарабатывают деньги через чужие компьютеры Скрипт майнинга криптовалюты как его удалить Picodi: Все скидки в одном месте
Picodi: Все скидки в одном месте Как открыть BIOS на ноутбуке
Как открыть BIOS на ноутбуке