Zavod intitle все публикации пользователя. Расширенный поиск и язык запросов. Язык запросов поисковой системы
Получение частных данных не всегда означает взлом - иногда они опубликованы в общем доступе. Знание настроек Google и немного смекалки позволят найти массу интересного - от номеров кредиток до документов ФБР.
WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.К интернету сегодня подключают всё подряд, мало заботясь об ограничении доступа. Поэтому многие приватные данные становятся добычей поисковиков. Роботы-«пауки» уже не ограничиваются веб-страницами, а индексируют весь доступный в Сети контент и постоянно добавляют в свои базы не предназначенную для разглашения информацию. Узнать эти секреты просто - нужно лишь знать, как именно спросить о них.
Ищем файлы
В умелых руках Google быстро найдет все, что плохо лежит в Сети, - например, личную информацию и файлы для служебного использования. Их частенько прячут, как ключ под половиком: настоящих ограничений доступа нет, данные просто лежат на задворках сайта, куда не ведут ссылки. Стандартный веб-интерфейс Google предоставляет лишь базовые настройки расширенного поиска, но даже их будет достаточно.
Ограничить поиск по файлам определенного вида в Google можно с помощью двух операторов: filetype и ext . Первый задает формат, который поисковик определил по заголовку файла, второй - расширение файла, независимо от его внутреннего содержимого. При поиске в обоих случаях нужно указывать лишь расширение. Изначально оператор ext было удобно использовать в тех случаях, когда специфические признаки формата у файла отсутствовали (например, для поиска конфигурационных файлов ini и cfg, внутри которых может быть все что угодно). Сейчас алгоритмы Google изменились, и видимой разницы между операторами нет - результаты в большинстве случаев выходят одинаковые.

Фильтруем выдачу
По умолчанию слова и вообще любые введенные символы Google ищет по всем файлам на проиндексированных страницах. Ограничить область поиска можно по домену верхнего уровня, конкретному сайту или по месту расположения искомой последовательности в самих файлах. Для первых двух вариантов используется оператор site, после которого вводится имя домена или выбранного сайта. В третьем случае целый набор операторов позволяет искать информацию в служебных полях и метаданных. Например, allinurl отыщет заданное в теле самих ссылок, allinanchor - в тексте, снабженном тегом , allintitle - в заголовках страниц, allintext - в теле страниц.
Для каждого оператора есть облегченная версия с более коротким названием (без приставки all). Разница в том, что allinurl отыщет ссылки со всеми словами, а inurl - только с первым из них. Второе и последующие слова из запроса могут встречаться на веб-страницах где угодно. Оператор inurl тоже имеет отличия от другого схожего по смыслу - site . Первый также позволяет находить любую последовательность символов в ссылке на искомый документ (например, /cgi-bin/), что широко используется для поиска компонентов с известными уязвимостями.
Попробуем на практике. Берем фильтр allintext и делаем так, чтобы запрос выдал список номеров и проверочных кодов кредиток, срок действия которых истечет только через два года (или когда их владельцам надоест кормить всех подряд).
Allintext: card number expiration date /2017 cvv

Когда читаешь в новостях, что юный хакер «взломал серверы» Пентагона или NASA, украв секретные сведения, то в большинстве случаев речь идет именно о такой элементарной технике использования Google. Предположим, нас интересует список сотрудников NASA и их контактные данные. Наверняка такой перечень есть в электронном виде. Для удобства или по недосмотру он может лежать и на самом сайте организации. Логично, что в этом случае на него не будет ссылок, поскольку предназначен он для внутреннего использования. Какие слова могут быть в таком файле? Как минимум - поле «адрес». Проверить все эти предположения проще простого.

Inurl:nasa.gov filetype:xlsx "address"

Пользуемся бюрократией
Подобные находки - приятная мелочь. По-настоящему же солидный улов обеспечивает более детальное знание операторов Google для веб-мастеров, самой Сети и особенностей структуры искомого. Зная детали, можно легко отфильтровать выдачу и уточнить свойства нужных файлов, чтобы в остатке получить действительно ценные данные. Забавно, что здесь на помощь приходит бюрократия. Она плодит типовые формулировки, по которым удобно искать случайно просочившиеся в Сеть секретные сведения.
Например, обязательный в канцелярии министерства обороны США штамп Distribution statement означает стандартизированные ограничения на распространение документа. Литерой A отмечаются публичные релизы, в которых нет ничего секретного; B - предназначенные только для внутреннего использования, C - строго конфиденциальные и так далее до F. Отдельно стоит литера X, которой отмечены особо ценные сведения, представляющие государственную тайну высшего уровня. Пускай такие документы ищут те, кому это положено делать по долгу службы, а мы ограничимся файлами с литерой С. Согласно директиве DoDI 5230.24, такая маркировка присваивается документам, содержащим описание критически важных технологий, попадающих под экспортный контроль. Обнаружить столь тщательно охраняемые сведения можно на сайтах в домене верхнего уровня.mil, выделенного для армии США.
"DISTRIBUTION STATEMENT C" inurl:navy.mil

Очень удобно, что в домене.mil собраны только сайты из ведомства МО США и его контрактных организаций. Поисковая выдача с ограничением по домену получается исключительно чистой, а заголовки - говорящими сами за себя. Искать подобным образом российские секреты практически бесполезно: в доменах.ru и.рф царит хаос, да и названия многих систем вооружения звучат как ботанические (ПП «Кипарис», САУ «Акация») или вовсе сказочные (ТОС «Буратино»).

Внимательно изучив любой документ с сайта в домене.mil, можно увидеть и другие маркеры для уточнения поиска. Например, отсылку к экспортным ограничениям «Sec 2751», по которой также удобно искать интересную техническую информацию. Время от времени ее изымают с официальных сайтов, где она однажды засветилась, поэтому, если в поисковой выдаче не удается перейти по интересной ссылке, воспользуйся кешем Гугла (оператор cache) или сайтом Internet Archive.
Забираемся в облака
Помимо случайно рассекреченных документов правительственных ведомств, в кеше Гугла временами всплывают ссылки на личные файлы из Dropbox и других сервисов хранения данных, которые создают «приватные» ссылки на публично опубликованные данные. С альтернативными и самодельными сервисами еще хуже. Например, следующий запрос находит данные всех клиентов Verizon, у которых на роутере установлен и активно используется FTP-сервер.
Allinurl:ftp:// verizon.net
Таких умников сейчас нашлось больше сорока тысяч, а весной 2015-го их было на порядок больше. Вместо Verizon.net можно подставить имя любого известного провайдера, и чем он будет известнее, тем крупнее может быть улов. Через встроенный FTP-сервер видно файлы на подключенном к маршрутизатору внешнем накопителе. Обычно это NAS для удаленной работы, персональное облако или какая-нибудь пиринговая качалка файлов. Все содержимое таких носителей оказывается проиндексировано Google и другими поисковиками, поэтому получить доступ к хранящимся на внешних дисках файлам можно по прямой ссылке.

Подсматриваем конфиги
До повальной миграции в облака в качестве удаленных хранилищ рулили простые FTP-серверы, в которых тоже хватало уязвимостей. Многие из них актуальны до сих пор. Например, у популярной программы WS_FTP Professional данные о конфигурации, пользовательских аккаунтах и паролях хранятся в файле ws_ftp.ini . Его просто найти и прочитать, поскольку все записи сохраняются в текстовом формате, а пароли шифруются алгоритмом Triple DES после минимальной обфускации. В большинстве версий достаточно просто отбросить первый байт.

Расшифровать такие пароли легко с помощью утилиты WS_FTP Password Decryptor или бесплатного веб-сервиса .

Говоря о взломе произвольного сайта, обычно подразумевают получение пароля из логов и бэкапов конфигурационных файлов CMS или приложений для электронной коммерции. Если знаешь их типовую структуру, то легко сможешь указать ключевые слова. Строки, подобные встречающимся в ws_ftp.ini , крайне распространены. Например, в Drupal и PrestaShop обязательно есть идентификатор пользователя (UID) и соответствующий ему пароль (pwd), а хранится вся информация в файлах с расширением.inc. Искать их можно следующим образом:
"pwd=" "UID=" ext:inc
Раскрываем пароли от СУБД
В конфигурационных файлах SQL-серверов имена и адреса электронной почты пользователей хранятся в открытом виде, а вместо паролей записаны их хеши MD5. Расшифровать их, строго говоря, невозможно, однако можно найти соответствие среди известных пар хеш - пароль.

До сих пор встречаются СУБД, в которых не используется даже хеширование паролей. Конфигурационные файлы любой из них можно просто посмотреть в браузере.
Intext:DB_PASSWORD filetype:env

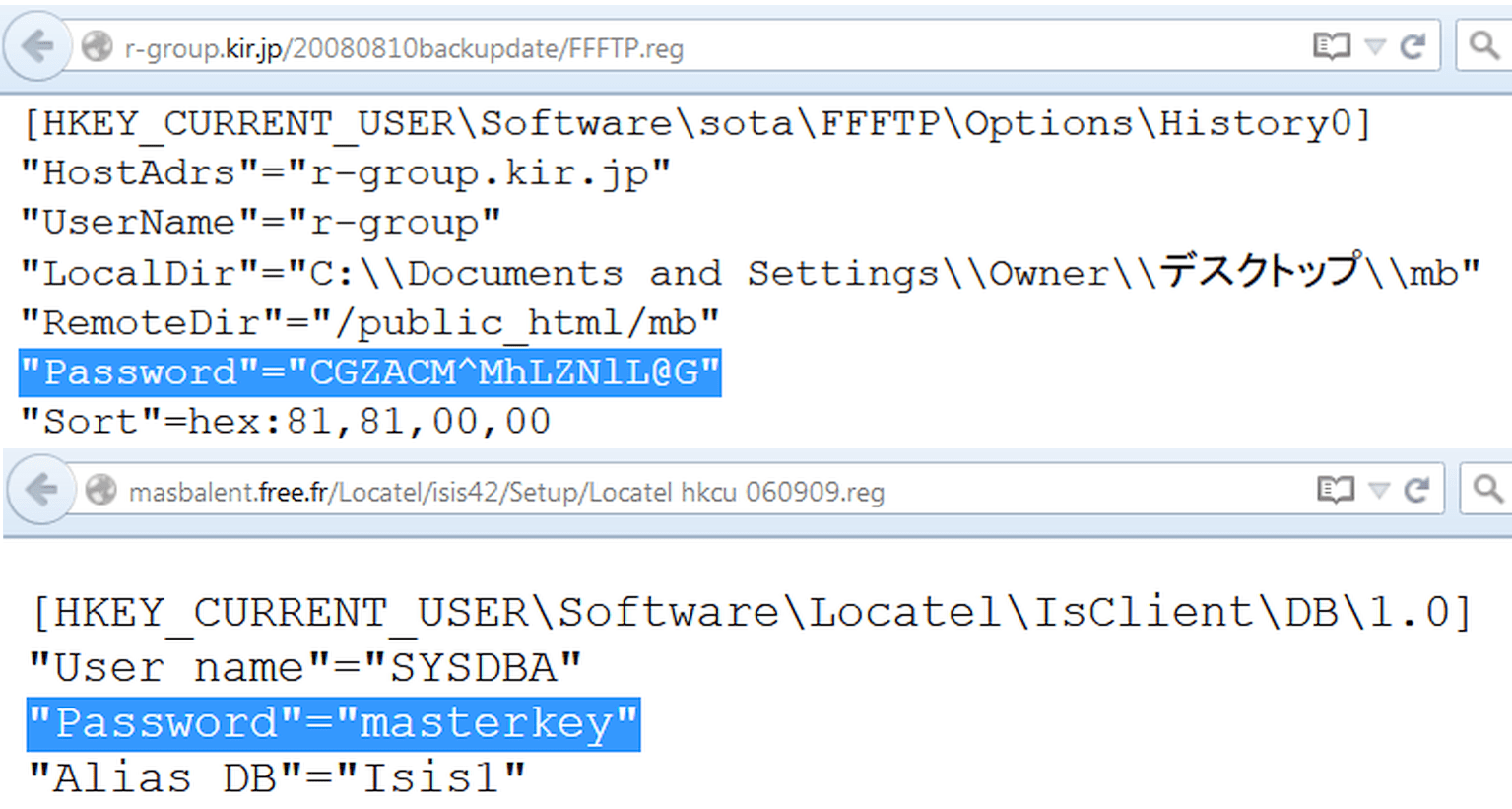
С появлением на серверах Windows место конфигурационных файлов отчасти занял реестр. Искать по его веткам можно точно таким же образом, используя reg в качестве типа файла. Например, вот так:
Filetype:reg HKEY_CURRENT_USER "Password"=
Не забываем про очевидное
Иногда добраться до закрытой информации удается с помощью случайно открытых и попавших в поле зрения Google данных. Идеальный вариант - найти список паролей в каком-нибудь распространенном формате. Хранить сведения аккаунтов в текстовом файле, документе Word или электронной таблице Excel могут только отчаянные люди, но как раз их всегда хватает.
Filetype:xls inurl:password

С одной стороны, есть масса средств для предотвращения подобных инцидентов. Необходимо указывать адекватные права доступа в htaccess, патчить CMS, не использовать левые скрипты и закрывать прочие дыры. Существует также файл со списком исключений robots.txt, запрещающий поисковикам индексировать указанные в нем файлы и каталоги. С другой стороны, если структура robots.txt на каком-то сервере отличается от стандартной, то сразу становится видно, что на нем пытаются скрыть.

Список каталогов и файлов на любом сайте предваряется стандартной надписью index of. Поскольку для служебных целей она должна встречаться в заголовке, то имеет смысл ограничить ее поиск оператором intitle . Интересные вещи находятся в каталогах /admin/, /personal/, /etc/ и даже /secret/.

Следим за обновлениями
Актуальность тут крайне важна: старые уязвимости закрывают очень медленно, но Google и его поисковая выдача меняются постоянно. Есть разница даже между фильтром «за последнюю секунду» (&tbs=qdr:s в конце урла запроса) и «в реальном времени» (&tbs=qdr:1).
Временной интервал даты последнего обновления файла у Google тоже указывается неявно. Через графический веб-интерфейс можно выбрать один из типовых периодов (час, день, неделя и так далее) либо задать диапазон дат, но такой способ не годится для автоматизации.
По виду адресной строки можно догадаться только о способе ограничить вывод результатов с помощью конструкции &tbs=qdr: . Буква y после нее задает лимит в один год (&tbs=qdr:y), m показывает результаты за последний месяц, w - за неделю, d - за прошедший день, h - за последний час, n - за минуту, а s - за секунду. Самые свежие результаты, только что ставшие известными Google, находится при помощи фильтра &tbs=qdr:1 .
Если требуется написать хитрый скрипт, то будет полезно знать, что диапазон дат задается в Google в юлианском формате через оператор daterange . Например, вот так можно найти список документов PDF со словом confidential, загруженных c 1 января по 1 июля 2015 года.
Confidential filetype:pdf daterange:2457024-2457205
Диапазон указывается в формате юлианских дат без учета дробной части. Переводить их вручную с григорианского календаря неудобно. Проще воспользоваться конвертером дат .
Таргетируемся и снова фильтруем
Помимо указания дополнительных операторов в поисковом запросе их можно отправлять прямо в теле ссылки. Например, уточнению filetype:pdf соответствует конструкция as_filetype=pdf . Таким образом удобно задавать любые уточнения. Допустим, выдача результатов только из Республики Гондурас задается добавлением в поисковый URL конструкции cr=countryHN , а только из города Бобруйск - gcs=Bobruisk . В разделе для разработчиков можно найти полный список .
Средства автоматизации Google призваны облегчить жизнь, но часто добавляют проблем. Например, по IP пользователя через WHOIS определяется его город. На основании этой информации в Google не только балансируется нагрузка между серверами, но и меняются результаты поисковой выдачи. В зависимости от региона при одном и том же запросе на первую страницу попадут разные результаты, а часть из них может вовсе оказаться скрытой. Почувствовать себя космополитом и искать информацию из любой страны поможет ее двухбуквенный код после директивы gl=country . Например, код Нидерландов - NL, а Ватикану и Северной Корее в Google свой код не положен.
Часто поисковая выдача оказывается замусоренной даже после использования нескольких продвинутых фильтров. В таком случае легко уточнить запрос, добавив к нему несколько слов-исключений (перед каждым из них ставится знак минус). Например, со словом Personal часто употребляются banking , names и tutorial . Поэтому более чистые поисковые результаты покажет не хрестоматийный пример запроса, а уточненный:
Intitle:"Index of /Personal/" -names -tutorial -banking
Пример напоследок
Искушенный хакер отличается тем, что обеспечивает себя всем необходимым самостоятельно. Например, VPN - штука удобная, но либо дорогая, либо временная и с ограничениями. Оформлять подписку для себя одного слишком накладно. Хорошо, что есть групповые подписки, а с помощью Google легко стать частью какой-нибудь группы. Для этого достаточно найти файл конфигурации Cisco VPN, у которого довольно нестандартное расширение PCF и узнаваемый путь: Program Files\Cisco Systems\VPN Client\Profiles . Один запрос, и ты вливаешься, к примеру, в дружный коллектив Боннского университета.
Filetype:pcf vpn OR Group

INFO
Google находит конфигурационные файлы с паролями, но многие из них записаны в зашифрованном виде или заменены хешами. Если видишь строки фиксированной длины, то сразу ищи сервис расшифровки.Пароли хранятся в зашифрованном виде, но Морис Массар уже написал программу для их расшифровки и предоставляет ее бесплатно через thecampusgeeks.com .
При помощи Google выполняются сотни разных типов атак и тестов на проникновение. Есть множество вариантов, затрагивающих популярные программы, основные форматы баз данных, многочисленные уязвимости PHP, облаков и так далее. Если точно представлять то, что ищешь, это сильно упростит получение нужной информации (особенно той, которую не планировали делать всеобщим достоянием). Не Shodan единый питает интересными идеями, но всякая база проиндексированных сетевых ресурсов!
Наверняка вы не одни раз слышали о таком замечательном поисковике, как Google. Полагаю, вам не раз приходилось его использовать, когда вы хотел что-нибудь узнать. Вот только находили ли вы то, чего хотели? Если вы так же часто как и я ищете ответы в Google, я думаю, вам будет полезна эта статья, потому что она расчитана сделать ваш поиск более быстрым и эффективным. Итак, для начала немного истории…
Google - искажённое написание английского слова «googol», придуманного Милтоном Сироттой, племянником американского математика Эдварда Кайзера, для обозначения числа, состоящего из единицы и ста нулей. Сейчас же имя Google носит лидер поисковых машин интернета, разработанный Google Inc.
Google занимает более 70% мирового рынка, а значит, семь из десяти находящихся в сети людей обращаются к его странице в поисках информации в интернете. Cейчас регистрирует ежедневно около 50 млн. поисковых запросов и индексирует более 8 миллиардов веб-страниц. Google может находить информацию на 101 языке. Google на конец августа 2004 года состояла из 132 тыс. машин, расположенных в разных точках планеты.
Google использует интеллектуальную технику анализа текстов, которая позволяет искать важные и вместе с тем релевантные страницы по вашему запросу. Для этого Google анализирует не только саму страницу, которая соответствует запросу, но и страницы, которые на нее ссылаются, чтобы определить ценность этой страницы для целей вашего запроса. Кроме того, Google предпочитает страницы, на которых ключевые слова, введенные вами, расположены недалеко друг от друга.
Интерфейс Google содержит довольно сложный язык запросов, позволяющий ограничить область поиска отдельными доменами, языками, типами файлов и т. д. Использование некоторых операторов этого языка позволяет сделать процесс поиска необходимой информации более гибким и точным. Рассмотрим некоторые из них.
Логическое «И» (AND):
По умолчанию при написании слов запроса через пробел Google ищет документы, содержащие все слова запроса. Это и соответствует оператору AND. Т.е. пробел равносилен оператору AND.
Например:
Кошки собаки попугаи зебры
Кошки AND собачки AND попугаи AND зебры
(оба запроса одинаковы)
Логическое «ИЛИ» (OR):
Пишется с помощью оператора OR. Обратите внимание, что оператор OR должен быть написан заглавными буквами. Относительно недавно появилась возможность написания логического «ИЛИ» в виде вертикальной черты (|), подобно тому, как это делается в Яндексе. Используется для поиска с несколькими вариантами необходимой информации.
Например:
Таксы длинношерстные OR гладкошерстные
Таксы длинношерстные | гладкошерстные
(оба запроса одинаковы)
Необходимо помнить, что запросы в Google не чувствительны к регистру! Т.е. запросы Остров Гренландия и остров гренландия будут абсолютно одинаковы.
Оператор «Плюс» (+):
Бывают ситуации, когда надо принудительно включить в текст какое-либо слово, которое может иметь варианты написания. Для этого используется оператор "+" перед обязательным словом. Предположим, если у нас запрос Один дома I, в результате запроса у нас появится ненужная информация об «Один дома II», «Один дома III» и совсем немного про «Один дома I». Если же у нас запрос вида Один дома +I, в результате будет информация только о фильме «Один дома I».
Например:
Газета +Заря
Уравнение Бернулли +математика
Исключение слов из запроса. Логическое «НЕ» (-):
Как известно, информационный мусор часто встречается при составлении запроса. Чтобы его удалить, стандартно используются операторы исключения – логическое «НЕ». В Google такой оператор представлен знаком «минус». Используя этот оператор, можно исключать из результатов поиска те страницы, которые содержат в тексте определенные слова. Используется, как и оператор "+", перед исключаемым словом.
Например:
Журавль колодец -птица
Мертвые души -роман
Поиск точной фразы (""):
Искать точную фразу на практике требуется либо для поиска текста определенного произведения, либо для поиска определенных продуктов или компаний, в которых название или часть описания представляет собой стабильно повторяющееся словосочетание. Чтобы справиться с такой задачей при помощи Гугла, требуется заключить запрос в кавычки (имеются в виду двойные кавычки, которые применяются, например, для выделения прямой речи).
Например:
Произведение «Тихий дон»
«На дворе было холодно, хотя это и не мешало Борису осуществить запланированное»
Кстати, Google позволяет вводить в сторку запроса не более 32 слов!
Усечение слова (*):
Иногда требуется искать информацию о словосочетании слов, в котором неизвестно одно или несколько слов. Для этих целей вместо неизвестных словв используется оператор "*". Т.е. "*" - любое слово или группа слов.
Например:
Мастер и *
Леонардо * Винчи
Оператор cache:
Поисковая машина хранит версию текста, которая проиндексирована поисковым пауком, в специальном хранилище в формате, называемом кэшем. Кэшированную версию страницы можно извлечь, если оригинальная страница недоступна (например, не работает сервер, на котором она хранится). Кэшированная страница показывается в том виде, в котором она хранится в базе данных поисковой машины и сопровождается надписью наверху страницы о том, что это страница из кэша. Там же содержится информация о времени создания кэшированной версии. На странице из кэша ключевые слова запроса подсвечены, причем каждое слово для удобства пользователя подсвечено своим цветом. Можно создать запрос, который сразу будет выдавать кэшированную версию страницы с определенным адресом: cache: адрес_страницы, где вместо «адрес_страницы» - адрес сохраненной в кэше страницы. Если требуется найти в кэшированной странице какую либо информацию, надо после адреса страницы через пробел написать запрос этой информации.
Например:
cache:www.bsd.com
cache:www.knights.ru турниры
Надо помнить, что пробела между ":" и адресом страницы быть не должно!
Опаратор filetype:
Как известно, Google индексирует не только html страницы. Если, к примеру, понадобилось найти какую-нибудь информацию в отличном от html типе файла, можно воспользоваться оператором filetype, который позволяет искать информацию в определенном типе файлов (html, pdf, doc, rtf...).
Например:
Спецификация html filetype:pdf
Сочинения filetype:rtf
Оператор info:
Оператор info позволяет увидеть информацию, которая известна Google об этой странице.
Например:
info:www.wiches.ru
info:www.food.healthy.com
Оператор site:
Этот оператор ограничивает поиск конкретным доменом или сайтом. То есть, если сделать запрос: маркетинг разведка site:www.acfor-tc.ru, то результаты будут получены со страниц, содержащих слова «маркетинг» и «разведка» именно на сайте «acfor-tc.ru», а не в других частях Интернета.
Например:
Музыка site:www.music.su
Книги site:ru
Оператор link:
Этот оператор позволяет увидеть все страницы, которые ссылаются на страницу, по которой сделан запрос. Так, запрос link:www.google.com выдаст страницы, в которых есть ссылки на google.com.
Например:
link:www.ozone.com
Друзья link:www.happylife.ru
Оператор allintitle:
Если запрос начать с оператора allintitle, что переводится как «все в заголовке», то Google выдаст тексты, в которых все слова запроса содержатся в заголовках (внутри тега TITLE в HTML).
Например:
allintitle: Бесплатный софт
allintitle: Скачать музыкальные альбомы
Оператор intitle:
Показывает страницы, в кoтopыx только то слово, которое стоит непосредственно после оператора intitle, содержится в заголовке, а все остальные слова запроса могут быть в любом месте текста. Если поставить оператор intitle перед каждым словом запроса, это будет эквивалентно использованию оператора allintitle.
Например:
Программы intitle: Скачать
intitle: Бесплатно intitle: скачать софт
Оператор allinurl:
Если запрос начинается с оператора allinurl, то поиск ограничен теми документами, в которых все слова запроса содержатся только в адресе страницы, то есть в url.
Например:
allinurl:rus games
allinurl:books fantasy
Оператор inurl:
Слово, которые расположено непосредственно слитно с оператором inurl, будет найдено только в адресе страницы Интернета, а остальные слова – в любом месте такой страницы.
Например:
inurl:books скачать
inurl:games кряк
Оператор related:
Этот оператор описывает страницы, которые «похожи» на какую-то конкретную страницу. Так, запрос related:www.google.com выдаст страницы со схожей с Google тематикой.
Например:
related:www.ozone.com
related:www.nnm.ru
Оператор define:
Этот оператор выполняет роль своего рода толкового словаря, позволяющего быстро получить определение того слова, которое введено после оператора.
Например:
define: Кенгуру
define: Материнская плата
Оператор поиска синонимов (~):
Если вы хотите найти тексты, содержащие не только ваши ключевые слова, но и их синонимы, то можно воспользоваться оператором "~" перед словом, к которому необходимо найти синонимы.
Например:
Виды ~метаморфоз
~Объектное ориентирование
Оператор диапозона (..):
Для тех, кому приходится работать с цифрами, Google дал возможность искать диапазоны между числами. Для того, чтобы найти все страницы, содержащие числа в неком диапазоне «от - до», надо между этими крайними значениями поставить две точки (..), то есть, оператор диапозона.
Например:
Купить книгу $100..$150
Численность населения 1913..1935
Вот все известные мне операторы языка запросов в Google. Надеюсь, они хоть как-то облегчат вам процесс поиска нужной информации. Во всяком случае, я ими пользуюсь очень часто и могу с уверенностью сказать, что при их использовании я трачу на поиск значительно меньше времени, ежели без них.
Удачи! И да пребудет с тобой Сила.
Теги: поиск,операторы,Google
А сегодня я расскажу еще про один поисковик, который используется пентестерами / хакерами — Google, точнее о скрытых возможностях Google.
Что такое гугл дорки?
Google Dork или Google Dork Queries (GDQ) — это набор запросов для выявления грубейших дыр в безопасности. Всего, что должным образом не спрятано от поисковых роботов.
Для краткости такие запросы называют гугл дорки или просто дорками, как и тех админов, чьи ресурсы удалось взломать с помощью GDQ.
Операторы Google
Для начала я хотел бы привести небольшой список полезных команд Google. Среди всех команд расширенного поиска Гугл нас интересуют главным образом вот эти четыре:
- site - искать по конкретному сайту;
- inurl - указать на то, что искомые слова должны быть частью адреса страницы / сайта;
- intitle - оператор поиска в заголовке самой страниц;
- ext или filetype - поиск файлов конкретного типа по расширению.
Также при создании Дорка надо знать несколько важных операторов, которые задаются спецсимволами.
- | - оператор OR он же вертикальный слеш (логическое или) указывает, что нужно отобразить результаты, содержащие хотя бы одно из слов, перечисленных в запросе.
- «» - оператор кавычки указывает на поиск точного соответствия.
- — - оператор минус используется для исключения из выдачи результатов с указанными после минуса словами.
- * - оператор звездочка, или астериск используют в качестве маски и означает «что угодно».
Где найти Гугл Дорки
Самые интересные дорки — свежие, а самые свежие — те, которые пентестер нашел сам. Правда, если слишком увлечетесь экспериментами, вас забанят в Google… до ввода капчи.
Если не хватает фантазии, можно попробовать найти свежие дорки в сети. Лучший сайт для поиска дорков — это Exploit-DB.
Онлайн-сервис Exploit-DB — это некоммерческий проект Offensive Security. Если кто не в курсе, данная компания занимается обучением в области информационной безопасности, а также предоставляет услуги пентеста (тестирования на проникновение).
База данных Exploit-DB насчитывает огромное количество дорков и уязвимостей. Для поиска дорков зайдите на сайт и перейдите на вкладку «Google Hacking Database».
База обновляется ежедневно. На верху вы можете найти последние добавления. С левой стороны дата добавления дорка, название и категория.
 Сайт Exploit-DB
Сайт Exploit-DB В нижней части вы найдете дорки отсортированные по категориям.
 Сайт Exploit-DB
Сайт Exploit-DB  Сайт Exploit-DB
Сайт Exploit-DB Еще один неплохой сайт — это . Там зачастую можно найти интересные, новые дорки, которые не всегда попадают на Exploit-DB.
Примеры использования Google Dorks
Вот примеры дорков. Экспериментируя с дорками, не забудьте про дисклеймер!
Данный материал носит информационный характер. Он адресован специалистам в области информационной безопасности и тем, кто собирается ими стать. Изложенная в статье информация предоставлена исключительно в ознакомительных целях. Ни редакция сайта www.сайт ни автор публикации не несут никакой ответственности за любой вред нанесенный материалом этой статьи.
Дорки для поиска проблем сайтов
Иногда бывает полезно изучить структуру сайта, получив список файлов на нем. Если сайт сделан на движке WordPress, то файл repair.php хранит названия других PHP-скриптов.
Тег inurl сообщает Google, что искать надо по первому слову в теле ссылки. Если бы мы написали allinurl, то поиск происходил бы по всему телу ссылки, а поисковая выдача была бы более замусоренной. Поэтому достаточно сделать запрос такого вида:
inurl:/maint/repair.php?repair=1
В результате вы получите список сайтов на WP, у которых можно посмотреть структуру через repair.php.
 Изучаем структуру сайта на WP
Изучаем структуру сайта на WP Массу проблем администраторам доставляет WordPress с незамеченными ошибками в конфигурации. Из открытого лога можно узнать как минимум названия скриптов и загруженных файлов.
inurl:"wp-content/uploads/file-manager/log.txt"
В нашем эксперименте простейший запрос позволил найти в логе прямую ссылку на бэкап и скачать его.
 Находим ценную инфу в логах WP
Находим ценную инфу в логах WP Много ценной информации можно выудить из логов. Достаточно знать, как они выглядят и чем отличаются от массы других файлов. Например, опенсорсный интерфейс для БД под названием pgAdmin создает служебный файл pgadmin.log. В нем часто содержатся имена пользователей, названия колонок базы данных, внутренние адреса и подобное.
Находится лог элементарным запросом:
ext:log inurl:"/pgadmin"
Бытует мнение, что открытый код - это безопасный код. Однако сама по себе открытость исходников означает лишь возможность исследовать их, и цели таких изысканий далеко не всегда благие.
К примеру, среди фреймворков для разработки веб-приложений популярен Symfony Standard Edition. При развертывании он автоматически создает в каталоге /app/config/ файл parameters.yml, где сохраняет название базы данных, а также логин и пароль.
Найти этот файл можно следующим запросом:
inurl:app/config/ intext:parameters.yml intitle:index.of
 ф Еще один файл с паролями
ф Еще один файл с паролями Конечно, затем пароль могли сменить, но чаще всего он остается таким, каким был задан еще на этапе развертывания.
Опенсорсная утилита UniFi API browser tool все чаще используется в корпоративной среде. Она применяется для управления сегментами беспроводных сетей, созданных по принципу «бесшовного Wi-Fi». То есть в схеме развертывания сети предприятия, в которой множество точек доступа управляются с единого контроллера.
Утилита предназначена для отображения данных, запрашиваемых через Ubiquiti’s UniFi Controller API. С ее помощью легко просматривать статистику, информацию о подключенных клиентах и прочие сведения о работе сервера через API UniFi.
Разработчик честно предупреждает: «Please do keep in mind this tool exposes A LOT OF the information available in your controller, so you should somehow restrict access to it! There are no security controls built into the tool…». Но кажется, многие не воспринимают эти предупреждения всерьез.
Зная об этой особенности и задав еще один специфический запрос, вы увидите массу служебных данных, в том числе ключи приложений и парольные фразы.
inurl:"/api/index.php" intitle:UniFi
Общее правило поиска: сначала определяем наиболее специфические слова, характеризующие выбранную цель. Если это лог-файл, то что его отличает от прочих логов? Если это файл с паролями, то где и в каком виде они могут храниться? Слова-маркеры всегда находятся в каком-то определенном месте - например, в заголовке веб-страницы или ее адресе. Ограничивая область поиска и задавая точные маркеры, вы получите сырую поисковую выдачу. Затем чистите ее от мусора, уточняя запрос.
Дорки для поиска открытых NAS
Домашние и офисные сетевые хранилища нынче популярны. Функцию NAS поддерживают многие внешние диски и роутеры. Большинство их владельцев не заморачиваются с защитой и даже не меняют дефолтные пароли вроде admin/admin. Найти популярные NAS можно по типовым заголовкам их веб-страниц. Например, запрос:
intitle:"Welcome to QNAP Turbo NAS"
выдаст список айпишников NAS производства QNAP. Останется лишь найти среди них слабозащищенный.
Облачный сервис QNAP (как и многие другие) имеет функцию предоставления общего доступа к файлам по закрытой ссылке. Проблема в том, что она не такая уж закрытая.
inurl:share.cgi?ssid=
 Находим расшаренные файлы
Находим расшаренные файлы Этот нехитрый запрос показывает файлы, расшаренные через облако QNAP. Их можно просмотреть прямо из браузера или скачать для более детального ознакомления.
Дорки для поиска IP-камер, медиасерверов и веб-админкок
Помимо NAS, с помощью продвинутых запросов к Google можно найти массу других сетевых устройств с управлением через веб-интерфейс.
Наиболее часто для этого используются сценарии CGI, поэтому файл main.cgi - перспективная цель. Однако встретиться он может где угодно, поэтому запрос лучше уточнить.
Например, добавив к нему типовой вызов?next_file. В итоге получим дорк вида:
inurl:"img/main.cgi?next_file"
Помимо камер, подобным образом находятся медиасерверы, открытые для всех и каждого. Особенно это касается серверов Twonky производства Lynx Technology. У них весьма узнаваемое имя и дефолтный порт 9000.
Для более чистой поисковой выдачи номер порта лучше указать в URL и исключить его из текстовой части веб-страниц. Запрос приобретает вид
intitle:"twonky server" inurl:"9000" -intext:"9000"
 Видеотека по годам
Видеотека по годам Обычно Twonky-сервер - это огромная медиатека, расшаривающая контент через UPnP. Авторизация на них часто отключена «для удобства».
Дорки для поиска уязвимостей
Большие данные сейчас на слуху: считается, что, если к чему угодно добавить Big Data, оно волшебным образом станет работать лучше. В реальности настоящих специалистов по этой теме очень мало, а при дефолтной конфигурации большие данные приводят к большим уязвимостям.
Hadoop - один из простейших способов скомпрометировать тера- и даже петабайты данных. Эта платформа с открытым исходным кодом содержит известные заголовки, номера портов и служебных страниц, по которым просто отыскать управляемые ей ноды.
intitle:"Namenode information" AND inurl:":50070/dfshealth.html"
 Big Data? Big vulnerabilities!
Big Data? Big vulnerabilities! Таким запросом с конкатенацией мы получаем поисковую выдачу со списком уязвимых систем на базе Hadoop. Можно прямо из браузера погулять по файловой системе HDFS и скачать любой файл.
Гугл Дорки — это мощный инструмент любого пентестера, о котором должен знать не только специалист в области информационной безопасности, но и обычный пользователь сети.
В прошлый раз мы рассмотрели , а на этот раз я расскажу как удалить мусор компьютера вручную , с помощью средств Windows и программ.
1. Для начала рассмотрим где же хранится мусор в операционных системах
В Windows ХР
Заходим и удаляем все в папках: Временные файлы Windows:
- C:\Documents and Settings\имя пользователя\Local Settings\History
- C:\Windows\Temp
- C:\Documents and Settings\имя пользователя\ Local Settings\Temp
- C:\Documents and Settings\Default User\Local Settings\History
Для Windows 7 и 8
Временные файлы Windows:
- C:\Windows\Temp
- C:\Users\Имя пользователя\AppData\Local\Temp
- C:\Users\Все пользователи \TEMP
- C:\Users\All Users\TEMP
- C:\Users\Default\AppData\Local\Temp
Кэш браузеров
Кэш оперы:
- C:\users\имя пользователя\AppData\Local\Opera\Opera\cache\
Кэш мозилы:
- C:\Users\имя пользователя\AppData\Local\Mozilla\Firefox\Profiles\ папка \Cache
Кэш гугл хрома (Chrome) :
- C:\Users\ имя пользователя \AppData\Local\Bromium\User Data\Default\Cache
- C:\Users\Пользователь\AppData\Local\Google\Chrome\User Data\Default\Cache
Или вбиваем в адресе chrome://version/ и видим путь к профилю. Там будет папка Cache
Временые файлы интернета:
- C:\Users\имя пользователя\AppData\Local\Microsoft\Windows\Temporary Internet Files\
Недавние документы:
- C:\Users\имя пользователя\AppData\Roaming\Microsoft\Windows\Recent\
Некоторые папки могут быть скрыты от посторонних глаз. Чтобы показать их нужно .
2. Очистка диска от временных и не используемых файлов используя
Стандартный инструмент «Очистка диска»
1. Зайдите в «Пуск» ->»Все программы» -> «Стандартные» -> «Служебные» и запустите программу «Очистка диска».
2. Выберите диск для очистки:

Начнется процесс сканирования диска…
3. Откроется окно с информацией о количестве места, занимаемом временными файлами:

Поставьте галки напротив разделов, которые вы хотите очистить и нажмите «ОК».
4. Но это еще не все . Если вы устанавливали Windows 7 не на чистый диск, а поверх ранее установленной операционной системы, у вас наверняка присутствуют такие занимающие много места папки, как Windows.old или $WINDOWS.~Q.
Кроме того, может иметь смысл удалить контрольные точки восстановления системы (кроме последней). Что бы выполнить эту операцию, повторите шаги 1-3, но на этот раз нажмите «Очистить системные файлы»:

5. После процедуры, описанной в п.2, у вас откроется то же окно, но наверху появится закладка «Дополнительно». Перейдите на нее.

В разделе «Восстановление системы и теневое копирование» нажмите «Очистить».
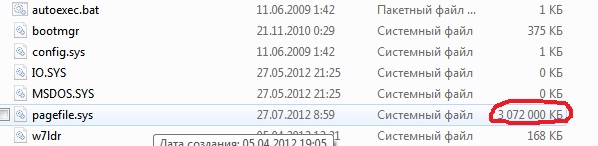
3. Файлы pagefile.sys и hiberfil.sys
Файлы расположены в корне системного диска и занимают довольно много места.
1. Файл pagefile.sys является системный файлом подкачки (виртуальная память). Удалить его нельзя (не рекомендуется так же его уменьшать), но зато его можно и даже нужно переместить на другой диск.
Делается это очень просто, откройте «Панель управления — Система и безопасность — Система» , выберите «Дополнительные параметры системы» в разделе «Быстродействие» нажмите «Параметры», переключитесь на закладку «Дополнительно» (или нажмите сочитание клавишь win+R откроется команда выполнить и там наберите SystemPropertiesAdvanced) и в разделе «Виртуальная память» нажмите «Изменить». Там можно выбрать местоположение файла подкачки и его размер (рекомендую оставить «Размер по выбору системы»).
4. Удаление не нужных программ с диска
Хороший способ освободить место на диске (и как дополнительный бонус увеличить производительность системы), это удалить не используемые программы.

Зайдите в панель управления и выберите «Удаление программ». Появится список в котором вы можете выбрать программу, которую вы хотите удалить и нажать «Удалить».
5. Дефрагментация
Дефрагментация жесткого диска, проводимая программой-дефрагментатором, позволяет упорядочить содержимое кластеров, то есть переместить их на диске так, чтобы кластеры с одним и тем же файлом стали размещаться последовательно, а пустые кластеры были объединены. Это приводит к увеличению скорости доступа к файлам, а значит и к некоторому повышению быстродействия компьютера, что при высоком уровне фрагментированности диска может оказаться достаточно заметным . Стандартная программа дифрагментации диска находится по пути: пуск>все программы>стандартные >служебные> дефрагментация диска

Вот так выглядит программа. В которой можно проанализировать диск, где программа покажет диаграмму фрагментированности диска и скажет нужно или не нужно выполнять дефрагментацию. Так же можно задать расписание когда будет производится дефрагментация диска. Это программа встроенная в Windows, так же есть и отдельные программы дефрагментации диска например которую скачать можно здесь:

Интерфейс её тоже достаточно прост.

Вот её преимущества над стандартной программой:

- Анализ перед дефрагментацией диска Делайте анализ диска перед дефрагментацией. После проведения анализа отображается диалоговое окно с диаграммой о проценте фрагментированных файлов и папок в диске и рекомендацией к действию. Анализ рекомендуется проводить регулярно, а дефрагментацию только после соответствующей рекомендации программы дефрагментации диска. Анализ дисков рекомендуется выполнять не реже одного раза в неделю. Если потребность в дефрагментации возникает редко, интервал выполнения анализа дисков можно увеличить до одного месяца.
- Анализ после добавления большого числа файлов После добавления большого количества файлов или папок диски могут стать чрезмерно фрагментированными, поэтому в таких случаях рекомендуется их проанализировать.
- Проверка наличия не менее 15% свободного пространства на диске Для полной и правильной дефрагментации с помощью программы «Дефрагментация диска» диск должен иметь не менее 15% свободного пространства. Программа «Дефрагментация диска» использует этот объем как область для сортировки фрагментов файлов. Если объем составляет менее 15% свободного пространства, то программа «Дефрагментация диска» выполнит только частичную дефрагментацию. Чтобы освободить дополнительное место на диске, удалите ненужные файлы или переместите их на другой диск.
- Дефрагментация после установки программного обеспечения или установки Windows Дефрагментируйте диски после установки программного обеспечения или после выполнения обновления или чистой установки Windows. После установки программного обеспечения диски часто фрагментируются, поэтому выполнение программы «Дефрагментация диска» помогает обеспечить наивысшую производительность файловой системы.
- Экономие времени на дефрагментацию дисков Можно немного сэкономить время, требуемое на дефрагментацию, если перед началом операции удалить из компьютера мусорные файлы, а также исключить из рассмотрения системные файлы pagefile.sys и hiberfil.sys, которые используются системой в качестве временных, буферных файлов и пересоздаются в начале каждой сессии Windows.
6. Удаляем ненужное из автозагрузки
7. Удаляем все ненужное с
Ну что вам не нужно на рабочем столе вы думаю сами для себя знаете. А как им пользоваться можете прочитать . , очень важная процедура, по этому не забывайте про неё!
Для любой компании важно защищать конфиденциальные данные. Утечка клиентских логинов и паролей или потеря системных файлов, размещенных на сервере, может не только повлечь за собой финансовые убытки, но и уничтожить репутацию самой, казалось бы, надежной организации. Автор статьи — Вадим Кулиш .
Учитывая все возможные риски, компании внедряют новейшие технологии и тратят огромные средства, пытаясь предотвратить несанкционированный доступ к ценным данным.
Однако задумывались ли вы, что помимо сложных и хорошо продуманных хакерских атак, существуют простые способы обнаружить файлы
, которые не были надежно защищены. Речь идет об операторах поиска — словах, добавляемых к поисковым запросам для получения более точных результатов. Но обо все по порядку.
Серфинг в Интернете невозможно представить без таких поисковых систем как Google, Yandex, Bing и других сервисов подобного рода. Поисковик индексируют множество сайтов в сети. Делают они это с помощью поисковых роботов, которые обрабатывают большое количество данных и делают их доступными для поиска.
Популярные операторы поисковых запросов Google
Использование следующих операторов позволяет сделать процесс поиска необходимой информации более точным:
* site: ограничивает поиск определенным ресурсом
Пример: запрос site:example.com найдет всю информацию, которую содержит Google для сайта example.com.
* filetype: позволяет искать информацию в определенном типе файлов
Пример: запрос покажет весь список файлов на сайте, которые присутствуют в поисковике Google.
* inurl: — поиск в URL ресурса
Пример: запрос site:example.com inurl:admin — ищет панель администрирования на сайте.
* intitle: — поиск в названии страницы
Пример: запрос site: example.com intitle:»Index of» — ищет страницы на сайте example.com со списком файлов внутри
* cache: — поиск в кэше Google
Пример: запрос cache:example.com вернет все закэшированные в системе страницы ресурса example.com
К сожалению, поисковые роботы не умеют определять тип и степень конфиденциальности информации. Поэтому они одинаково обрабатывают статью из блога, которая рассчитана на широкий круг читателей, и резервную копию базы данных, которая хранится в корневой директории веб-сервера и не подлежит использованию посторонними лицами.
Благодаря этой особенности, а также используя операторы поиска, злоумышленникам и удается обнаружить уязвимости веб-ресурсов, различные утечки информации (резервные копии и текст ошибок работы веб-приложения), скрытые ресурсы, такие как открытые панели администрирования, без механизмов аутентификации и авторизации.
Какие конфиденциальные данные могут быть найдены в сети?
Следует иметь в виду, что информация, которая может быть обнаружена поисковыми системами и потенциально может быть интересна хакерам, включает в себя:
* Домены третьего уровня исследуемого ресурса
Домены третьего уровня можно обнаружить с помощью слова «site:». К примеру, запрос вида site:*.example.com выведет все домены 3-го уровня для example.com. Такие запросы позволяют обнаружить скрытые ресурсы администрирования, системы контроля версий и сборки, а также другие приложения, имеющие веб-интерфейс.
* Скрытые файлы на сервере
В поисковую выдачу могут попасть различные части веб-приложения. Для их поиска можно воспользоваться запросом filetype:php site:example.com . Это позволяет обнаружить ранее недоступную функциональность в приложении, а также различную информацию о работе приложения.
* Резервные копии
Для поиска резервных копий используется ключевое слово filetype:. Для хранения резервных копий используются различные расширения файлов, но чаще всего используются расширения bak, tar.gz, sql. Пример запроса: site:*.example.com filetype:sql . Резервные копии часто содержат логины и пароли от административных интерфейсов, а также данные пользователей и исходный код веб-сайта.
* Ошибки работы веб-приложения
Текст ошибки может включать в себя различные данные о системных компонентах приложения (веб-сервер, база данных, платформа веб-приложения). Такая информация всегда очень интересна хакерам, так как позволяет получить больше информации об атакуемой системе и усовершенствовать свою атаку на ресурс. Пример запроса: site:example.com «warning» «error» .
* Логины и пароли
В результате взлома веб-приложения в сети Интернет могут появиться данные пользователей этого сервиса. Запрос filetype:txt «login» «password» позволяет найти файлы с логинами и паролями. Таким же образом можно проверить, не взломали ли вашу почту или какой-либо аккаунт. Просто сделайте запрос filetype:txt имя_пользователя_или_электронная_почта» .
Комбинации ключевых слов и строки поиска, используемые для обнаружения конфиденциальной информации, называются Google Dorks.
Специалисты Google собрали их в своей публичной базе данных Google Hacking Database . Это дает возможность представителю компании, будь то CEO, разработчик или вебмастер, выполнить запрос в поисковике и определить, насколько хорошо защищены ценные данные. Все дорки распределены по категориям для облегчения поиска.
Нужна помощь? Закажите консультацию специалистов по тестированию защищенности a1qa.
Как Google Dorks вошли в историю хакерства
Напоследок несколько примеров того, как Google Dorks помогли злоумышленникам получить важную, но ненадежно защищенную информацию:
Пример из практики №1. Утечка конфиденциальных документов на сайте банка
В рамках анализа защищенности официального сайта банка было обнаружено огромное количество pdf-документов. Все документы были обнаружены с помощью запроса «site:bank-site filetype:pdf». Интересным оказалось содержимое документов, так как там были планы помещений, в которых располагались отделения банка по всей стране. Это информация была бы очень интересна грабителям банков.
Пример из практики №2. Поиск данных платежных карт
Очень часто при взломе интернет-магазинов злоумышленники получают доступ к данным платежных карт пользователей. Для организации совместного доступа к этим данным злоумышленники используют публичные сервисы, которые индексируются Google. Пример запроса: «Card Number» «Expiration Date» «Card Type» filetype:txt.
Однако не стоит ограничиваться базовыми проверками. Доверьте комплексную оценку вашего продукта a1qa. Ведь хищение данных дешевле предотвратить, чем устранять последствия.
 Самый тонкий ноутбук 15 дюймов
Самый тонкий ноутбук 15 дюймов Свернуть одинаковые значения 1с 8
Свернуть одинаковые значения 1с 8 Переименовать колонку таблицы значений 1с 8
Переименовать колонку таблицы значений 1с 8