Рассеяние на статистически неровной поверхности с произвольными корреляционными свойствами. Корреляционно-регрессионный анализ в Excel: инструкция выполнения
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:


После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.


В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» - первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» - второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:



Теперь стали видны и данные регрессионного анализа.
И корреляция
1.1. Понятие регрессии
Парной регрессией называется уравнение связи двух переменных у и х
вида y = f (x ),
где у – зависимая переменная (результативный признак); х – независимая, объясняющая переменная (признак-фактор).
Различают линейные и нелинейные регрессии.
Линейная регрессия описывается уравнением: y = a + b × x +e .
Нелинейные регрессии делятся на два класса: регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, и регрессии, нелинейные по оцениваемым параметрам.
Примеры регрессий, нелинейных по объясняющим переменным, но ли-
нейных по оцениваемым параметрам:
· полиномы разных степеней
· равносторонняя гипербола: ![]()
Примеры регрессий, нелинейных по оцениваемым параметрам:
· степенная ![]()
· показательная ![]()
· экспоненциальная ![]()
Наиболее часто применяются следующие модели регрессий:
– прямой ![]()
– гиперболы ![]()
– параболы
– показательной функции
– степенная функция ![]()
1.2. Построение уравнения регрессии
Постановка задачи. По имеющимся данным n наблюдений за совместным
изменением двух параметров x и y {(xi ,yi ), i=1,2,...,n} необходимо определить
аналитическую зависимость ŷ=f(x) , наилучшим образом описывающую данные наблюдений.
Построение уравнения регрессии осуществляется в два этапа (предполагает решение двух задач):
– спецификация модели (определение вида аналитической зависимости
ŷ=f(x) );
– оценка параметров выбранной модели.
1.2.1. Спецификация модели
Парная регрессия применяется, если имеется доминирующий фактор, который и используется в качестве объясняющей переменной.
Применяется три основных метода выбора вида аналитической зависимости:
– графический (на основе анализа поля корреляций);
– аналитический, т. е. исходя из теории изучаемой взаимосвязи;
– экспериментальный, т. е. путем сравнения величины остаточной дисперсии D ост или средней ошибки аппроксимации , рассчитанных для различных
моделей регрессии (метод перебора).
1.2.2. Оценка параметров модели
Для оценки параметров регрессий, линейных по этим параметрам, используется метод наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических значений ŷx при тех же значениях фактора x минимальна, т. е.

В случае линейной регрессии параметры а и b находятся из следующей
системы нормальных уравнений метода МНК:
 (1.1)
(1.1)
Можно воспользоваться готовыми формулами, которые вытекают из этой
 (1.2)
(1.2)
Для нелинейных уравнений регрессии, приводимых к линейным с помощью преобразования (x , y ) → (x’ , y’ ), система нормальных уравнений имеет
вид (1.1) в преобразованных переменных x’ , y’ .
Коэффициент b при факторной переменной x имеет следующую интерпретацию: он показывает, на сколько изменится в среднем величина y при изменении фактора x на 1 единицу измерения .
Гиперболическая регрессия :
x’ = 1/x ; y’ = y .
Уравнения (1.1) и формулы (1.2) принимают вид

Экспоненциальная регрессия:
![]()
Линеаризующее преобразование: x’ = x ; y’ = lny .
Модифицированная экспонента
: ![]() , (0 < a
1 < 1).
, (0 < a
1 < 1).
Линеаризующее преобразование: x’ = x ; y’ = ln │y – К│.
Величина предела роста K выбирается предварительно на основе анализа
поля корреляций либо из качественных соображений. Параметр a 0 берется со
знаком «+», если y х > K и со знаком «–» в противном случае.
Степенная функция:
Линеаризующее преобразование: x’ = ln x ; y’ = ln y .
Показательная функция:
Линеаризующее преобразование: x’ = x ; y’ = lny .
https://pandia.ru/text/78/146/images/image026_7.jpg" width="459" height="64 src=">
Парабола второго порядка :
Парабола второго порядка имеет 3 параметра a 0, a 1, a 2, которые определяются из системы трех уравнений

1.3. Оценка тесноты связи
Тесноту связи изучаемых явлений оценивает линейный коэффициент
парной корреляции rxy для линейной регрессии (–1 ≤ r xy ≤ 1)
и индекс корреляции ρxy
для нелинейной регрессии ![]()
Имеет место соотношение

Долю дисперсии, объясняемую регрессией , в общей дисперсии результативного признака у характеризует коэффициент детерминации r2xy (для линейной регрессии) или индекс детерминации (для нелинейной регрессии).
Коэффициент детерминации – квадрат коэффициента или индекса корреляции.
Для оценки качества построенной модели регрессии можно использовать
показатель (коэффициент, индекс) детерминации R 2 либо среднюю ошибку аппроксимации.
Чем выше показатель детерминации или чем ниже средняя ошибка аппроксимации, тем лучше модель описывает исходные данные.
Средняя ошибка аппроксимации – среднее относительное отклонение
расчетных значений от фактических

Построенное уравнение регрессии считается удовлетворительным, если
значение не превышает 10–12 %.
1.4. Оценка значимости уравнения регрессии, его коэффициентов,
коэффициента детерминации
Оценка значимости всего уравнения регрессии в целом осуществляется с
помощью F -критерия Фишера.
F- критерий Фишера заключается в проверке гипотезы Но о статистической незначимости уравнения регрессии. Для этого выполняется сравнение
фактического F факт и критического (табличного) F табл значений F- критерия
Фишера.
F факт определяется из соотношения значений факторной и остаточной
дисперсий, рассчитанных на одну степень свободы

где n – число единиц совокупности; m – число параметров при переменных.
Для линейной регрессии m = 1 .
Для нелинейной регрессии вместо r 2 xy используется R 2.
F табл – максимально возможное значение критерия под влиянием случайных факторов при степенях свободы k1 = m , k2 = n – m – 1 (для линейной регрессии m = 1) и уровне значимости α.
Уровень значимости α – вероятность отвергнуть правильную гипотезу
при условии, что она верна. Обычно величина α принимается равной 0,05 или
Если F табл < F факт, то Н0 -гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если F табл > F факт, то гипотеза Но не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Для оценки статистической значимости коэффициентов линейной регрессии и линейного коэффициента парной корреляции применяется
t- критерий Стьюдента и рассчитываются доверительные интервалы каждого
из показателей.
Согласно t- критерию выдвигается гипотеза Н0 о случайной природе показателей, т. е. о незначимом их отличии от нуля. Далее рассчитываются фактические значения критерия t факт для оцениваемых коэффициентов регрессии и коэффициента корреляции путем сопоставления их значений с величиной стандартной ошибки

Стандартные ошибки параметров линейной регрессии и коэффициента
корреляции определяются по формулам
 Сравнивая фактическое и критическое (табличное) значения t-
статистики
Сравнивая фактическое и критическое (табличное) значения t-
статистики
t табл и t факт принимают или отвергают гипотезу Но.
t табл – максимально возможное значение критерия под влиянием случайных факторов при данной степени свободы k = n– 2 и уровне значимости α.
Связь между F- критерием Фишера (при k 1 = 1; m =1) и t- критерием Стьюдента выражается равенством
Если t табл < t факт, то Но отклоняется, т. е. a, b и не случайно отличаются
от нуля и сформировались под влиянием систематически действующего фактора х. Если t табл > t факт, то гипотеза Но не отклоняется и признается случайная природа формирования а, b или https://pandia.ru/text/78/146/images/image041_2.jpg" width="574" height="59">
F табл определяется из таблицы при степенях свободы k 1 = 1, k 2 = n –2 и при
заданном уровне значимости α. Если F табл < F факт, то признается статистическая значимость коэффициента детерминации. В формуле (1.6) величина m означает число параметров при переменных в соответствующем уравнении регрессии.
1.5. Расчет доверительных интервалов
Рассчитанные значения показателей (коэффициенты a , b , ) являются
приближенными, полученными на основе имеющихся выборочных данных.
Для оценки того, насколько точные значения показателей могут отличаться от рассчитанных, осуществляется построение доверительных интервалов.
Доверительные интервалы определяют пределы, в которых лежат точные значения определяемых показателей с заданной степенью уверенности, соответствующей заданному уровню значимости α.
Для расчета доверительных интервалов для параметров a и b уравнения линейной регрессии определяем предельную ошибку Δ для каждого показателя:
Величина t табл представляет собой табличное значение t- критерия Стьюдента под влиянием случайных факторов при степени свободы k = n –2 и заданном уровне значимости α.
Формулы для расчета доверительных интервалов имеют следующий вид:
https://pandia.ru/text/78/146/images/image045_3.jpg" width="188" height="62">
где t γ – значение случайной величины, подчиняющейся стандартному нормальному распределению, соответствующее вероятности γ = 1 – α/2 (α – уровень значимости);
z’ = Z (rxy) – значение Z- распределения Фишера, соответствующее полученному значению линейного коэффициента корреляции rxy .
Граничные значения доверительного интервала (r– , r+ ) для rxy получаются
из граничных значений доверительного интервала (z– , z+ ) для z с помощью
функции, обратной Z- распределению Фишера

1.6. Точечный и интервальный прогноз по уравнению линейной
регрессии
Точечный прогноз заключается в получении прогнозного значения уp , которое определяется путем подстановки в уравнение регрессии
соответствующего (прогнозного
) значения x
p
![]()
Интервальный прогноз заключается в построении доверительного интервала прогноза, т. е. нижней и верхней границ уpmin, уpmax интервала, содержащего точную величину для прогнозного значения https://pandia.ru/text/78/146/images/image050_2.jpg" width="37" height="44 src=">
и затем строится доверительный интервал прогноза , т. е. определяются нижняя и верхняя границы интервала прогноза

Контрольные вопросы:
1. Что понимается под парной регрессией?
2. Какие задачи решаются при построении уравнения регрессии?
3. Какие методы применяются для выбора вида модели регрессии?
4. Какие функции чаще всего используются для построения уравнения парной регрессии?
5. Какой вид имеет система нормальных уравнений метода наименьших квадратов в случае линейной регрессии?
6. Какой вид имеет система нормальных уравнений метода наименьших квадратов в случае гиперболической, показательной регрессии?
7. По какой формуле вычисляется линейный коэффициент парной корреляции r xy ?
8. Как строится доверительный интервал для линейного коэффициента парной корреляции?
9. Как вычисляется индекс корреляции?
10. Как вычисляется и что показывает индекс детерминации?
11. Как проверяется значимость уравнения регрессии и отдельных коэффициентов?
12. Как строится доверительный интервал прогноза в случае линейной регрессии?
Лабораторная работа № 1
Задание.1 На основании данных табл. П1 для соответствующего варианта (табл. 1.1):
1. Вычислить линейный коэффициент парной корреляции.
2. Проверить значимость коэффициента парной корреляции.
3. Построить доверительный интервал для линейного коэффициента парной корреляции.
Задание. 2 На основании данных табл. П1 для соответствующего варианта (табл. 1.1):
1. Построить предложенные уравнения регрессии, включая линейную регрессию.
2. Вычислить индексы парной корреляции для каждого уравнения.
3. Проверить значимость уравнений регрессии и отдельных коэффициентов линейного уравнения.
4. Определить лучшее уравнение регрессии на основе средней ошибки аппроксимации.
5. Построить интервальный прогноз для значения x = x max для линейного
уравнения регрессии.
Требования к оформлению результатов
Отчет о лабораторной работе должен содержать разделы:
1. Описание задания;
2. Описание решения лабораторной работы (по этапам);
3. Изложение полученных результатов.

Таблица П1
Исходные данные к лабораторным работам № 1, 2
Наличие предметов длительного пользования в домашних хозяйствах по регионам Российской Федерации (европейская часть территории без республик Северного Кавказа) (по материалам выборочного обследования бюджетов домашних хозяйств; на 100 домохозяйств; штук)
План лекции:
1.Детерминированные и случайные функции.
2.Основные вероятностные характеристики случайных процессов.
8.1. Детерминированные и случайные функции
До сих пор поведение САУ исследовалось при определенных, заданных во времени управляющих и возмущающих воздействиях (ступенчатая функция, импульсная функция, гармоническое воздействие и т.д.). При этих условиях состояние системы может быть точно предсказано для любого момента времени заранее. Система полностью определена и называется в этом смысле детерминированной.
Однако во многих случаях характер воздействия бывает таким, что его нельзя считать определенной функцией времени. Воздействие может принимать с течением времени самые разнообразные случайные значения. В таких случаях мы можем оценить только вероятность появления той или иной формы воздействия в тот или иной момент времени. Это происходит потому, что сама природа реального управляющего или возмущающего воздействия такова, что его величина в каждый момент времени и процесс его изменения с течением времени зависят от множества разнообразных величин, которые случайным образом могут комбинироваться друг с другом.
Строго оптимальное поведение системы при наличии случайных воздействий неосуществимо. Однако можно говорить о наиболее вероятном приближении к тому или иному оптимуму. Обычно при этом приходится идти на определенный компромисс.
Случайная функция отличается от регулярной тем, что мы не можем утверждать, что она в данный момент времени будет иметь определенное значение. Мы можем говорить лишь о вероятности того, что в данный момент t=t значение функции x(t) заключается между значениями x и x+x . Понятие случайной функции – это обобщенное понятие, и говорить о значении функции в данный момент мы, в сущности, не можем. Однако в конкретно наблюдаемой кривой случайного процесса эти значения существуют. Конкретно наблюдаемая кривая случайного процесса называется реализацией случайной функции. Реализации могут иметь и определенные значения, и определенные производные (рис.8.1). Множество различных реализаций и обобщается понятием “случайная функция”.

Рис. 8.1. Отдельные реализации случайной функции времени
Если график семейства реализаций случайной функции рассечь вертикальной линией, то получим случайную величину x(t i) для заданного момента времени t i .
8.2. Основные вероятностные характеристики
случайных процессов
8.2.1. функция распределения и плотность вероятности
Для характеристики случайной функции служат функции распределения вероятности и плотности вероятности.
Под функцией распределения вероятности , часто называемой интегральным законом распределения, понимают вероятность того, что случайная величина примет значение меньше некоторого фиксированного значения.
Производная от функции распределения вероятности носит название плотности вероятности или дифференциального закона распределения.
Одномерная функция распределения вероятности относится только к одному какому-либо сечению случайной функции:
Она показывает вероятность того, что текущее значение случайной функции x(t) в момент времени t=t 1 меньше заданной величины х 1 .
Соответственно, одномерная плотность вероятности p 1 (x 1 ,t 1) есть производная от интегрального распределения вероятности F 1 (x 1 ,t 1 ) и имеет вид:
 . (8.2)
. (8.2)
Величина выражает вероятность того, что случайная функция x(t) в момент времени t=t 1 находится в интервале от x до .
Рассмотрим теперь всевозможные пары значений х, полученные в два разных момента времени: t 1 и t 2 . Двумерное распределение вероятности имеет вид:
Двумерное распределение вероятности относится к двум произвольным сечениям x(t 1), x(t 2) случайной функции и выражает вероятность того, что в момент времени t 1 случайная функция x(t) меньше х 1 , а в момент t 2 - меньше х 2 . Соответствующая двумерная плотность вероятности имеет вид
 . (8.4)
. (8.4)
Некоторые типы случайных процессов полностью характеризуются одномерными или двумерными плотностями вероятности. Например, так называемый чисто случайный процесс или «белый шум » полностью характеризуется одномерной плотностью вероятности.
Значения x(t) в этом процессе, взятые в различные моменты времени t 1 , t 2 , ..., совершенно независимы друг от друга. Вероятность совпадения событий, заключающихся в нахождении x(t) между х 1 и в момент t=t 1 и между x 2 и в момент t=t 2 равна произведению вероятностей каждого из этих событий. Поэтому
т. е. все плотности вероятности определяются одномерными плотностями.
Примером процесса, полностью характеризуемого двумерной плотностью вероятности, служит Марковский случайный процесс . Это такой процесс, для которого вероятность нахождения x(t) в заданном интервале (x n , x n +dx n) в момент t=t n , зависит только от состояния в предшествующий момент t n -1 и совершенно не зависит от состояния в другие моменты времени, т.е. от более глубокой предыстории.
Стационарный случайный процесс есть аналог установившегося процесса в детерминированной системе. Статистический характер стационарного процесса неизменен во времени.
В строгом смысле стационарным случайным процессом называют такой процесс, в котором функции распределения всех порядков не зависят от положения начала отсчета времени, т.е.
Из этих соотношений следует, что одномерные функция распределения и плотность вероятности стационарного процесса вообще не зависят от времени т.е.
 (8.7)
(8.7)
Функции распределения и плотности вероятности второго порядка для стационарного случайного процесса при одинаковых x 1 и x 2 остаются неизменными, если разность рассматриваемых моментов времени постоянна:
 (8.8)
(8.8)
Для оценки точности линейных САУ при решении многих прикладных задач достаточно знать первые два момента процесса: математическое ожидание и корреляционную функцию. Эти характеристики являются неслучайными функциями или величинами и представляют собой результат вероятностного усреднения различных функций случайных процессов.
Свойства стохастических процессов, определяемые двумя первыми моментами, изучаются с помощью корреляционной теории. Кроме корреляционного анализа, основанного на прямом рассмотрении случайных сигналов во времени, существует также метод, основанный на рассмотрении частотных составляющих случайных сигналов, спектральный анализ. Корреляционный и спектральный анализы широко используются в инженерной практике.
8.2.2. Математическое ожидание, дисперсия
и корреляционная функция случайного процесса
Зная одномерное распределение вероятности, можно определить математическое ожидание m(t) случайной функции x(t) или одномерный момент первого порядка:
![]() (8.9)
(8.9)
где P 1 (x, t) - плотность вероятности, x(t) - случайная функция.
Математическим ожиданием или средним (по множеству) значением случайной функции x(t) называют среднеарифметическое значение бесконечного множества реализаций , т. е. это такая неслучайная функция m x (t) , вокруг которой группируются все реализации данного случайного процесса и которая полностью определяется одномерным законом распределения.
Разность ![]() называют центрированной случайной функцией.
называют центрированной случайной функцией.
Математическое ожидание центрированной случайной функции тождественно равно нулю:
![]() .
.
В дальнейшем будем рассматривать только центрированные случайные функции и кружочек над х опускается.
Практически математическое ожидание может быть определено по реализациям. Для этого фиксируется значение аргумента t. Тогда при t=t 1 значение реализаций x 1 (t 1), x 2 (t 1),..., x N (t 1) представляет собой обычную случайную величину. Математическое ожидание случайной величины находим как среднеарифметическое значение:
![]() (8.10)
(8.10)
где i = 1, 2,..., n – фиксированное значение времени; = 1, 2,…, N - номер реализации.
На основании подсчета, проведенного для различных t=t i , можно построить график m x (t i) .
Среднее значение не полностью характеризует случайный процесс. При равных средних значениях процессы могут иметь различные отклонения. Поэтому для характеристики случайного процесса вводится понятие дисперсии.
Дисперсией случайной функции x(t) называют неслучайную и неотрицательную функцию аргумента t, представляющую собой среднее значение квадрата разности между случайной функцией и ее средним значением, или среднее значение квадрата отклонения случайной функции от ее среднего значения.
Она характеризует интенсивность отклонений относительно среднего значения и, так же как математическое ожидание, определяется одномерным законом распределения. Размерность дисперсии равна квадрату размерности случайной величины. Дисперсия регулярной функции равна нулю.
Среднеквадратическое отклонение равно корню квадратному из дисперсии:
![]() . (8.12)
. (8.12)
Введенные понятия иллюстрируются рис. 8.2. Математическое ожидание случайного процесса x(t) представляет собой некоторую среднюю кривую, около которой располагаются все возможные отдельные реализации этого процесса, а дисперсия D x (t) или среднеквадратическое отклонение характеризует рассеяние отдельных возможных реализаций около этой средней кривой. В общем случае среднеквадратическое отклонение меняется с течением времени. Указанные характеристики m(t) и D(t) для каждого данного момента времени являются средними по множеству.

Рис. 8.2. Изменение среднего значения и отдельных реализаций
случайного процесса:
а - при сильной связи между значениями случайной функции;
б - при слабой связи
При обработке результатов испытаний дисперсия случайной функции рассчитывается по реализациям с помощью формулы
 . (8.13)
. (8.13)
Для случайной функции одномерное распределение вероятности и получаемые на ее основе характеристики (математическое ожидание и дисперсия) еще не являются достаточными для оценки случайного процесса во времени.
Необходимо установить связь между значениями случайного процесса в разные моменты времени. На рис. 8.2 приведены реализации двух случайных функций, которые имеют равные математические ожидания и дисперсии, но по характеру отличаются друг от друга. Если случайная функция (см. рис. 8.2, а) при некотором t приняла значение, лежащее выше m(t), то можно утверждать, что и ближайшее значение реализации случайной функции пройдет выше m(t). Во втором случае (рис. 8.2, б) этого может и не быть. Значит, разница между рассматриваемыми случайными функциями проявляется в характере связи между значениями случайной функции для различных аргументов t 1 и t 2 .
Зная двумерную функцию распределения p 2 (x 1 ,t 1 ;x 2 ,t 2), можно определить не только математическое ожидание m x (t) и дисперсию D(t), но и момент второго порядка, характеризующий связь между значениями случайной функции в различные моменты времени.
Математическое ожидание произведения значений центрированной случайной функции, взятых при двух моментах времени t 1 и t 2 называют корреляционной или автокорреляционной функцией:
В этом выражении P 2 (x 1 ,t 1 ;x 2 ,t 2)
определяет вероятность того, что в момент времени t 1
значение случайного процесса находится в пределах ![]() ,
а в момент времени t 2
-в пределах .
,
а в момент времени t 2
-в пределах .
Если аргументы корреляционной функции равны между собой (t 1 =t 2 =t), то
![]() (8.15)
(8.15)
т. е. корреляционная функция для одного и того же сечения равна математическому ожиданию квадрата случайной функции. Для центрированной функции x(t) при t 1 =t 2 =t будем иметь
![]()
т. е. корреляционная функция равна дисперсии случайной функции.
Для характеристики статистической взаимосвязи различных случайных функций, действующих на одну и ту же систему, пользуются понятиями совместного распределения вероятности и взаимной корреляционной функции. Для функций f(t) и совместная функция распределения вероятности имеет вид
и означает вероятность того, что в момент времени t=t 1 значение f(t 1) меньше f, а в момент времени t=t 2 значение меньше . Совместная плотность вероятности
 . (8.17)
. (8.17)
Соответственно взаимной корреляционной функцией двух случайных центрированных функций f и называется математическое ожидание произведения этих функций, взятых при различном времени:
Случайные функции называют коррелированными, если их взаимная корреляционная функция не равна тождественно нулю, и некоррелированными при равенстве ее нулю.
8.3. Стационарные случайные процессы.
Эргодическая гипотеза
План лекции:
1. Стационарные случайные процессы.
2. Эргодические случайные процессы.
8.3.1. Стационарные случайные процессы
Различные случайные процессы по степени зависимости их статистических характеристик от времени делят на стационарные и нестационарные.
Наиболее просто осуществляется анализ случайных процессов, статистические характеристики которых не зависят от текущего времени. Такие процессы называют стационарными.
Реальные физические процессы в большей или меньшей степени приближаются к стационарным процессам. Многие из них, например тепловые шумы, можно с большой точностью считать стационарными. К стационарным относятся также колебания самолета относительно установившегося горизонтального полета, шумы в радиоэлектронной аппаратуре, качка корабля и др.
Ко многим нестационарным процессам применяют результаты, полученные при исследовании стационарных процессов. Практически анализу подвергаются только обладающие конечной длительностью отрезки реализаций, и если на этих отрезках времени исследуемые процессы мало отличаются от стационарных, то к ним можно применять теорию стационарных процессов.
Различают стационарность в узком и широком смысле.
Стационарным в узком смысле называют процесс x(t), если его n -мерная плотность вероятности при любом n зависит только от величины интервалов t 2 - t 1 ,...,t n - t 1 и не зависит от положения этих интервалов в области изменения аргумента t.
Стационарным в широком смысле называют процесс x(t), математическое ожидание которого постоянно:
а корреляционная функция R x (t 1 ,t 2 ) зависит только от разности ; при этом корреляционную функцию обозначают

союз советскихсаэащишпаиРЕСПУБЛИК госуддрств-:ннцй компо дк пдм изот:ткн ет сси открыт ПИСАНИЕ ИЗОБРЕТЕНИ и тво СССР 1977.(54) УСТРОЙСТВО ДЛЯ ОПР МЕТРОВ ЭКСПОНЕНЦИАЛЬНО КОРРЕЛЯЦИОННОЙ ФУНКЦИИ (57) Изобретение относ вычислительной техники использовано при иссле чайных процессов в зад ДЕЛЕНИЯ ПАРОСИНУСНОЙ ся к облас может быт ванин слуах автомат С:.80;,3 дшш 4 006 6 ческого управления, идентификациии т,д. Цель изобретения - расширениефункциональных возможностей за счетопределения последовательности некоррелированных дискретных значений исследуемого случайного процесса. Цельдостигается введением в известное устройство генератора синхроимпульсов,аналого-цифрового и цифроаналоговогопреобразователей, первого и второгоключей, счетчика и блока сравнения,Новые блоки и соответствующие функциональные связи позволяют определить некоррелированные дискретныезначения исследуемого процесса, т.е.синтезировать последовательность некоррелированных случайных величин,1 ил, 4 Изобретение относится к области вычислительной техники и может бытьиспользовано при исследовании слу-.чайных процессов в задачах автоматического управления идентификациии т.д,Цель изобретения - расширениефункциональных вазможностей за счетопределения последовательности некоррелированных дискретных значенийисследуемого случайного процесса,На чертеже представлена структур ная схема устройства,Устройство содержит усилительограничитель 1, блок 2 среднего числа пересечений, блок 3 экспоненциального сглаживания, оцноканальныйкоррелятор 4, вычислительный блок 5блок б возведения в степень, блок 7умножения, блок 8 деления, блок 9сравнения, цифроаналоговый преобра-.зователь 10, счетчик 11, первыйкл 1 оч 12, аналого-цифровой преобразователь 13, второй ключ 14, генератор 15 синхроимпульсав, выход 1 б некоррелированного значения случайного процесса.Устройство работает следующим Образом,Усилитель-ограничитель 1 преобразует исследуемьп случайный процесс в знаковый сигнал, В блоке 2 среднего числа пересечений измеряется среднее число пересечений нулевого уровня которое с точнастно до коэффициента пропорциональности совпадает с параметром ь затухания: экспоненци ально-косинусной корреляционной функ" ции (ЭККФ), аппроксимирующей знако вую корреляционную функцию исследуемого случайного процесса. Знаковый сигнал подвергается экспоненциапьному сглаживанию в блоке. 3, а коррелятор 4 определяет корреляционный момент сигналов на выходе блока 3 экспоненциального сглаживания, Известначто вьгхаднаи сиг нал ко 1)релятора р включенного таким образом, пропорционален первому коэффициенту разложения корреляционной функции в ряд Лагерра от аргументас, гдепараметр затухания экспоненциального сглаживающего фильтра. В вычислительном блохе 5 по сигналу с блока 2 и коррелятора 4 оценивается коэффициент, определяющий частоту колебательнасти корреляционной функции по формуле:Нараме:р " поступает с выхода вычислительного блока 5 на вход бло - г:а б возведения в степень, где осуон шести,еяется вычисление величины /пугем возведения 9 в степень 0,05. Отот сигнал подается на первый вход блока 1 умножения, на второй вход которого поступает оценка параметра Ф с выхода блока 2 среднего числа пересечений. В блоке 7 умножения выО,1числя е тс я з нач сние М, к о то ро е по цае тс я на вход блока 8 деления, где ос ущсс тпл я е тс я деление по с то яннай в еличины, равной 0 , б 1 , в с о отв ета 1 сгвии с формулой с = О,б 1/К/3 . Быггислепнсе значение интервала корреляции оц ЗК 1 М поступает на первый вход блока 9 сравнения. С информационного входа устройства исследуемь.й случайный процесс через аналогоцифровой преобразователь 13 поступает на упраезляющий вход первого ключа 12, При этом аналоговое напряжение, соответствующее значениюс выхода блока 8 деления поступает на первый вход блока 9 сравнения. На второй вход блока 9 сравнения поступает с выхода цифроаналогового преобразователя 1 О аналоговое напряжение, соответствующее текущему времени случяйнага п 1 эацесса т, . При этом счет текущего" времени т., осуществляеся н счетчике 11 который осуществляет считывание периодической по следовательносги синхроимпульсов. настпа 1 опих па его счетный вход саьехода зторого ключа 14, Синхроимнульсы езырабатываются генератором 15 сннхроимпульсов и поступают на входсчет 1 пгка.только при открытом втором клоче 14. Ключ 14 открывается таль.,са при наличии на входе устраи ства исследуемого случайного процесЛри наличии на первом входе кзпо-.а 1, напряжения, соответствующего случайному процессу, он открывается и сипхроимпульсы, поступающие на его второй вход, приходят на вход счетчика 11. Так как период следования импульсе:з постоянен и известен, количество считанных импульсов даетинформацию о текущем времени случайного процесса. Выход счетчика 11 соединен с входом цифроаналогового преобразователя, с выхода которого ана20 тель Е. ЕфимоваМ.Хаданич СостРедактор С. Патрушева Техр орректар А. Тясодписное 73/52 Тираж 671 ВНИИПИ Государственного по делам изобретений и 113035, Москва, Ж, РаушсЗаказ мнтета СС открытииая наб., д. 4/5 роизводственно-полиграфическое предприятие, г. Ужгород, ул. Проектная, 4 логовое напряжение, соответствующеетекущему времени, поступает на второй вход блока 9 сравнения и сравнивается с аналоговым значением,При выполнении условия= 1, сигнал с выхода равенства блока сравнения открывает первый ключ 12 и текущее некоррелированное значение случайного процесса в цифровой формепоступает на выход 16 устройства иодновременно на вход установки нулясчетчика 11 для его обнуления. Формула и з обретения5 Устройство для определения параметров экспоненциально-косинусной корреляционной Функции по авт.св.9 696487, о т л и ч а ю щ е е с я тем, что, с целью расширения функциональных возможностей за счет определения последовательности некоррелированных дискретных значений исследуемого случайного процесса, в него дополнительно введены генератор сиихроимпульсов, аналого-цифровойпреобразователь, цифроаналоговый преобразователь, первый ключ, второйключ, счетчик и блок сравнения, выход равенства которого соединен с управляющим входом первого ключа, информационный вход которого соединенс выходом аналого-цифрового преобразователя, вход которого является чнформационным входом устройства и соединен с управляющим входом второгоключа, информационный вход которогосоединен с выходом генератора синхраимпульсов, выход второго ключасоединен со счетным входом счетчика,выход которого подключен к входу цифроаналогового преобразователя, выходкоторого соединен с первым информационным входам блока сравнения, второй информационный вход которого соединен с выходом блока деления, выход первого ключа соединен с входамустановки нуля счетчика и являетсявыходом некоррелированного значенияслучайного процесса устройства.г
Заявка
3853239, 24.10.1984
ВОЕННО-ВОЗДУШНАЯ ИНЖЕНЕРНАЯ ОРДЕНА ЛЕНИНА И ОРДЕНА ОКТЯБРЬСКОЙ РЕВОЛЮЦИИ КРАСНОЗНАМЕННАЯ АКАДЕМИЯ ИМ. ПРОФ. Н. Е. ЖУКОВСКОГО
БУРБА АЛЕКСАНДР АЛЕКСЕЕВИЧ, МОНСИК ВЛАДИСЛАВ БОРИСОВИЧ, ОПАРЫШЕВ ВАЛЕРИЙ ВЛАДИМИРОВИЧ
МПК / Метки
Код ссылки
Устройство для определения параметров экспоненциально косинусной корреляционной функции
Похожие патенты
С атмосферой, а в глухой камере установлена пружина.На фиг. 1 изображен пневматический блок сравнения; на фиг. 2 - схема блока при выполнении узла ограничения в виде дросселя; 20 на фиг. 3 - схема блока при выполнении узла ограничения в виде соединения одномембранного элемента с дросселем; на фиг. 4 - узел ограничения в виде одномембранного элемента с обратным клапаном, 25Пневматический блок сравнения (фиг. 11 содержит входной одномембранный элемент 1, камеры которого соединены с входными каналами Р, и Р, а сопло через узел 2,ограничения и дроссель 3 - с атмосферой и с глухой 30 4. Проточная камера эле ссель б соединена с источ епосредственно с выхюдньтх257874 ние Р,м, до величины давления питания. Если Рг)Р 2, то мембрана элемента 1...
Задатчика 9 расходамОНОмера, прямой к инверсный ныхОдывторого триггера 42 соедццэнь 1 соответственно с у-, ранляющимц входамиключей 35 и 36 входы которых саедкнены и являются пятым входам блокасравнения, который соединен с выходом второго регулятора 1 концентрации мономера в шцхте, а выходы ключей 35 ц 36 соэдпнены соотне 1 стненно с пернымц вхадамк третьего 39 цчетвертого 40 элементов сравнения,вторые входы которых соединены к являются шестым входам блока сравнения,который соединен с входом задатчкка22 расхода вознратного растворителя, 5 Оиннерсный выход третьего триггера 43является выходом блока сравнения цсоединен с нхадами первого 1 и второго 2 ключей ц входом второго элемента ИЛИ 28. 55Основным элементам устройстваавтоматического...
Подводимое к зджн,)у 1, поступает через схему 2 (ири наличии нд сс втором входе разрешаюцго потенциала) в линейный аналого-цифровой прсобразовд Гель 3 и непосредственно - в аналого-цифроиои квадратор 11, При каждом запуск, производимом Выходным иъ 1 пуль(Ом схсм 1 Я ср 113 нсни 51, преобразователь 3 прсоб)разуе Напряжение в пропорциондлы)ос число и 1 пу 1013 (кОэфициент пронорципальности К). д нд выходе квадратора 11 появляются и)янульсы, ч ло КОТОРЫХ ПРОПОРЦИОНЯЛЩО КБДДРДТ) НсНР 5 Же 1131 я Унеслед) см 010 сл) Яйного процесс.С выхода преобразователя 3 импульсы подаются на схему 4, а с выхода квадр пора 11 - на схему 12 и могут проходить через эти схемы только тогда, когда триггер 16 н 1 ходится в единичном положении. 11 сходнос...
При исследовании вопросов зависимости или независимости двух или более сечений случайных процессов знание лишь математического ожидания и дисперсии с.п. не достаточно.
Для определения связи между различными случайными процессами используется понятие корреляционной функции – аналог понятия ковариации случайных величин (см. Т.8)
Корреляционной (ковариационной,
автоковариационной, автокорреляционной)
функцией случайного процесса называется
неслучайная функция
двух аргументов
называется
неслучайная функция
двух аргументов
 равна
корреляционному моменту соответствующих
сечений
равна
корреляционному моменту соответствующих
сечений и
и :
:
или (с
учётом обозначения центрированной
случайной функции
 )
имеем
)
имеем
Приведём
основные свойства корреляционной
функции
 случайного
процесса
случайного
процесса .
.
1. Корреляционная функция при одинаковых
значениях аргументов равна дисперсии
с.п.
Действительно,
Доказанное свойство позволяет вычислить м.о. и корреляционную функцию являющимися основными характеристиками случайного процесса, необходимость в подсчёте дисперсии отпадает.
2. Корреляционная функция не меняется относительно замены аргументов, т.е. является симметрической функцией относительно своих аргументов: .
Это свойство непосредственно выводится из определения корреляционной функции.
3. Если к случайному процессу прибавить
неслучайную функцию, то корреляционная
функция не меняется, т.е. если
 ,
то.
Другими словами
,
то.
Другими словами
является периодической функцией относительно любой неслучайной функции.
Действительно, из цепочки рассуждений
следует, что . Отсюда получим требуемое свойство 3.
4. Модуль корреляционной функции не превосходит произведения с.к.о., т.е.
Доказательство свойства 4. проводится
аналогично как в пункте 12.2. (теорема
12..2), с учётом первого свойства
корреляционной функции с.п.
 .
.
5. При умножении с.п. на
неслучайный множитель
на
неслучайный множитель её корреляционная функция умножится
на произведение
её корреляционная функция умножится
на произведение ,
т.е., если
,
т.е., если ,
то
,
то
5.1. Нормированная корреляционная функция
Наряду с корреляционной функцией с.п.
рассматривается также нормированная
корреляционная функция
(или
автокорреляционная
функция
) определяемая
равенством
определяемая
равенством
 .
.
Следствие. На основании свойства 1 имеет место равенство
 .
.
По своему смыслу
 аналогичен коэффициенту корреляции
для с.в., но не является постоянной
величиной, а зависит от аргументов
аналогичен коэффициенту корреляции
для с.в., но не является постоянной
величиной, а зависит от аргументов и
и .
.
Перечислим свойства нормированной корреляционной функции :
1.

2.

3.
 .
.
Пример 4.
Пусть с.п. определяется
формулой,
т.е. с.в.,
с.в.,
распределена
по нормальному закону с

Найти корреляционную и нормированную
функции случайного процесса

Решение. По определению имеем
т.е.
 Отсюда с учётом определения нормированной
корреляционной функции и результатов
решения предыдущих примеров получим
Отсюда с учётом определения нормированной
корреляционной функции и результатов
решения предыдущих примеров получим =1,
т.е.
=1,
т.е. .
.
5.2. Взаимная корреляционная функция случайного процесса
Для определения степени зависимости сечений двух случайных процессов используют корреляционную функцию связи или взаимную корреляционную функцию.
Взаимной корреляционной функцией двух
случайных процессов
 и
и называется неслучайная функция
называется неслучайная функция двух независимых аргументов
двух независимых аргументов и
и ,
которая при каждой паре значений
,
которая при каждой паре значений и
и равна корреляционному моменту двух
сечений
равна корреляционному моменту двух
сечений и
и
Два с.п.
 и
и называютсянекоррелированными,
если
их взаимная корреляционная функция
тождественно равна нулю, т.е. если для
любых
называютсянекоррелированными,
если
их взаимная корреляционная функция
тождественно равна нулю, т.е. если для
любых и
и имеет место
имеет место Если же для любых
Если же для любых и
и окажется
окажется ,
то случайные процессы
,
то случайные процессы и
и называютсякоррелированными
(илисвязанными
).
называютсякоррелированными
(илисвязанными
).
Рассмотрим свойства взаимной корреляционной функции, которые непосредственно выводятся из её определения и свойств корреляционного момента (см. 12.2):
1.При одновременной перестановке индексов и аргументов взаимная корреляционная функция не меняется, то есть
2. Модуль взаимной корреляционной функции двух случайных процессов не превышает произведения их средних квадратичных отклонений, то есть
3. Корреляционная функция не изменится,
если к случайным процессам и
и прибавить неслучайные функции
прибавить неслучайные функции и
и соответственно, то есть
соответственно, то есть ,
где соответственно
,
где соответственно и
и
4. Неслучайные множители
 можно
вынести за знак корреляции, то есть,
если
можно
вынести за знак корреляции, то есть,
если и, то
и, то
5. Если
 ,
то.
,
то.
6. Если случайные процессы
 и
и некоррелированные
, то корреляционная
функция их суммы равна сумме их
корреляционных функций, то есть.
некоррелированные
, то корреляционная
функция их суммы равна сумме их
корреляционных функций, то есть.
Для оценки степени зависимости сечений
двух с.п. используют также нормированную
взаимную корреляционную функцию
 ,
определяемую равенством:
,
определяемую равенством:
Функция
 обладает теми же свойствами, что и
функция
обладает теми же свойствами, что и
функция
 ,
но свойство 2
,
но свойство 2
заменяется
на следующее двойное неравенство
 ,
т.е. модуль нормированной взаимной
корреляционной функции не превышает
единицы.
,
т.е. модуль нормированной взаимной
корреляционной функции не превышает
единицы.
Пример 5.
Найти взаимную корреляционную
функцию двух с.п. и
и ,
где
,
где случайная
величина, при этом
случайная
величина, при этом
Решение. Так как,.
 Как Qualcomm испортила смартфоны LG, HTC и Sony
Как Qualcomm испортила смартфоны LG, HTC и Sony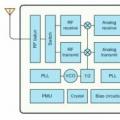 Управление с андроида по wifi
Управление с андроида по wifi Лаборатория информационной безопасности
Лаборатория информационной безопасности